Transformer 中的 position embedding 的设计
前言
Transformer 使用 Attention 结构来进行建模,在 NLP 和 CV 领域都有比较好的效果,其主要结构如下:
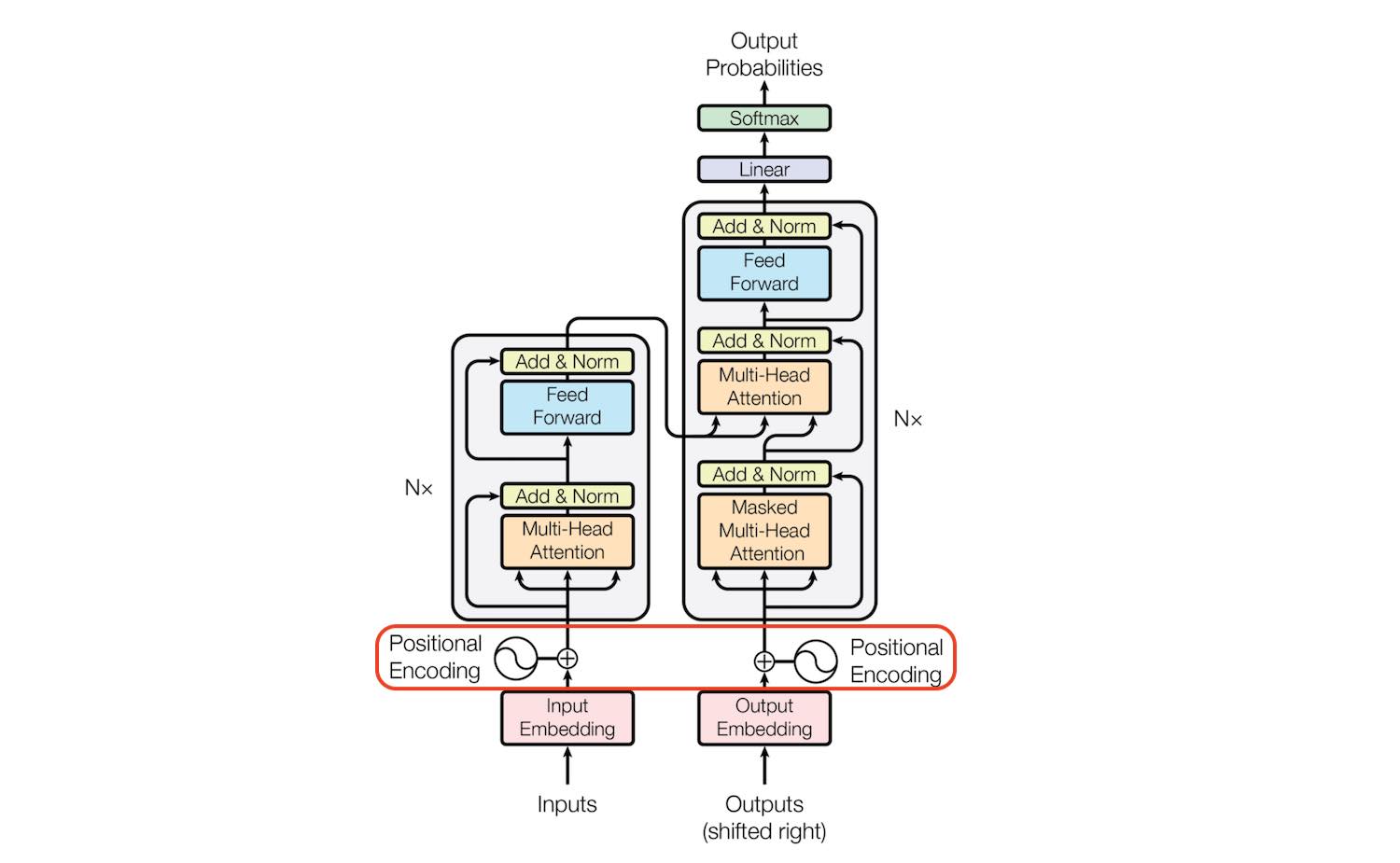
如果只取左边的部分,则退化为 BERT 类结构。 如果只取右边部分,则变成 GPT 类结构。
Transformer 使用 Attention 结构来进行建模,在 NLP 和 CV 领域都有比较好的效果,其主要结构如下:
如果只取左边的部分,则退化为 BERT 类结构。 如果只取右边部分,则变成 GPT 类结构。
Github:https://github.com/openai/gpt-2 、https://github.com/openai/gpt-3
GPT 系列是历史非常悠久的论文了,gpt1 甚至在 bert 之前就发布了。 但在下游任务上的表现,并没有 bert 亮眼,所以一直默默无闻。最近 chatgpt 大火,又把 gpt 的论文翻出来复习一下。
标题、时间、会议、领域、code、paper 链接
Paper: NeurIPS 2019
Code: https://github.com/microsoft/unilm
这是一篇比较老的论文了,在很多后续的论文中都看到了 unilm 的身影,于是周末又翻出来看了看。UNILM 模型可以同时支持内容理解任务和生成类任务,通过三种语言模型任务来实现,单向语言模型(左到右,又到左)、双向语言模型和句子预测模型。
标题、时间、会议、领域、code、paper 链接
GLM 于 2021 年发表于 arxiv / code 上,论文提出了一种新的通用语言模型 GLM(General Language Model)。 GLM,使用自回归填空目标进行预训练,可以针对各种自然语言理解和生成任务进行微调。