Unified Language Model Pre-training for Natural Language Understanding and Generation
基本信息
标题、时间、会议、领域、code、paper 链接
Paper: NeurIPS 2019
Code: https://github.com/microsoft/unilm
这是一篇比较老的论文了,在很多后续的论文中都看到了 unilm 的身影,于是周末又翻出来看了看。UNILM 模型可以同时支持内容理解任务和生成类任务,通过三种语言模型任务来实现,单向语言模型(左到右,又到左)、双向语言模型和句子预测模型。
创新点
概述
这篇论文中是解决了一个新问题,还是用一个新的方法解决了一个传统问题;创新点在哪里,有什么贡献。
论文通过使用三种预训练语言模型,对 NLU 和 NLG 任务同时进行了支持。而且我认为相较于 bert 这种双向语言模型来说, UNILM 的三种语言模型在相同数据集的前提下,可以学习到更多的知识。我们这里对比一下常见的 NLP 预训练任务。
常见网络设计
AR(AutoRegression Language Model)
自回归模型,根据前边或后边出现的 tokens 预测当前的 token,比如 GPT 、ELMO,最主要的特点是单向的。
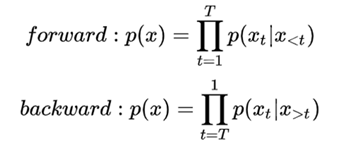
优点为,对自然语言生成类任务比较友好,符合生成任务的生成过程,一个字一个字的一直生成下去。
缺点为,只能单向的利用语义信息,而不能同时使用上下文信息,在理解任务上来说效果比较差。
AE(AutoEncoder Language Model)
自编码语言,通过上下文信息来预测当前被 mask 的 token,比如 BERT、Word2Vec 等。
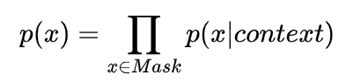
优点为,能够很好的同时使用上下文的信息,在理解类任务(比如话题、分类、实体识别)等下游任务上效果比较好。
缺点的话,在生成类的任务上,表现的不太好。
BERT
因为 bert 在 NLP 任务中的重要性,我们单独把 bert 拿出来说一下。BERT一共有两个任务,分别为:
- MLM (Masked Language Model)

经典的 mask 任务,分为三步实现:
1、在 encoder 后增加分类层;
2、根据词表和分类层的结果,得出预测的词;
3、根据真实文本和预测文本计算 loss;
- NSP ( next sentence prediction )

下一句预测任务
1、在句子前插入 [CLS] 标签,并在每一句的结束位置插入 [SEP]。将 token embedding 、 sentence embedding、 postion embedding 进行 add 运算。
2、根据 CLS 位的 embedding,过一个变形矩阵从而实现一个简单的分类层,然后做一个相关性的判断。
解决方法
具体如何实现的
UNILM 也是一个多层的 Transformer 网络,与 BERT 类似,同时支持单向LM、双向 LM、seq2seq 训练方式,在生成任务和理解任务上都有较好的表现。

根据 mask 的生成方式不同,实现多种语言模型:
- 单向训练模型,mask 词可以看到的是其单侧的 words,另一半的 words 全 mask 掉。
- 双向语训模型,mask 词可以看到周围的所有词
- seq2seq模型:左边的句子是 source sequence ,右边的句子是需要生成的句子, target sequence,所以 source sequence 是可以完全看到的, target sequence 可以看到已生成的部分。
优势:
- 训练任务之间共享参数;
- 更多的任务避免模型容易过拟合;
- 同时支持 NLU 和 NLG 任务;
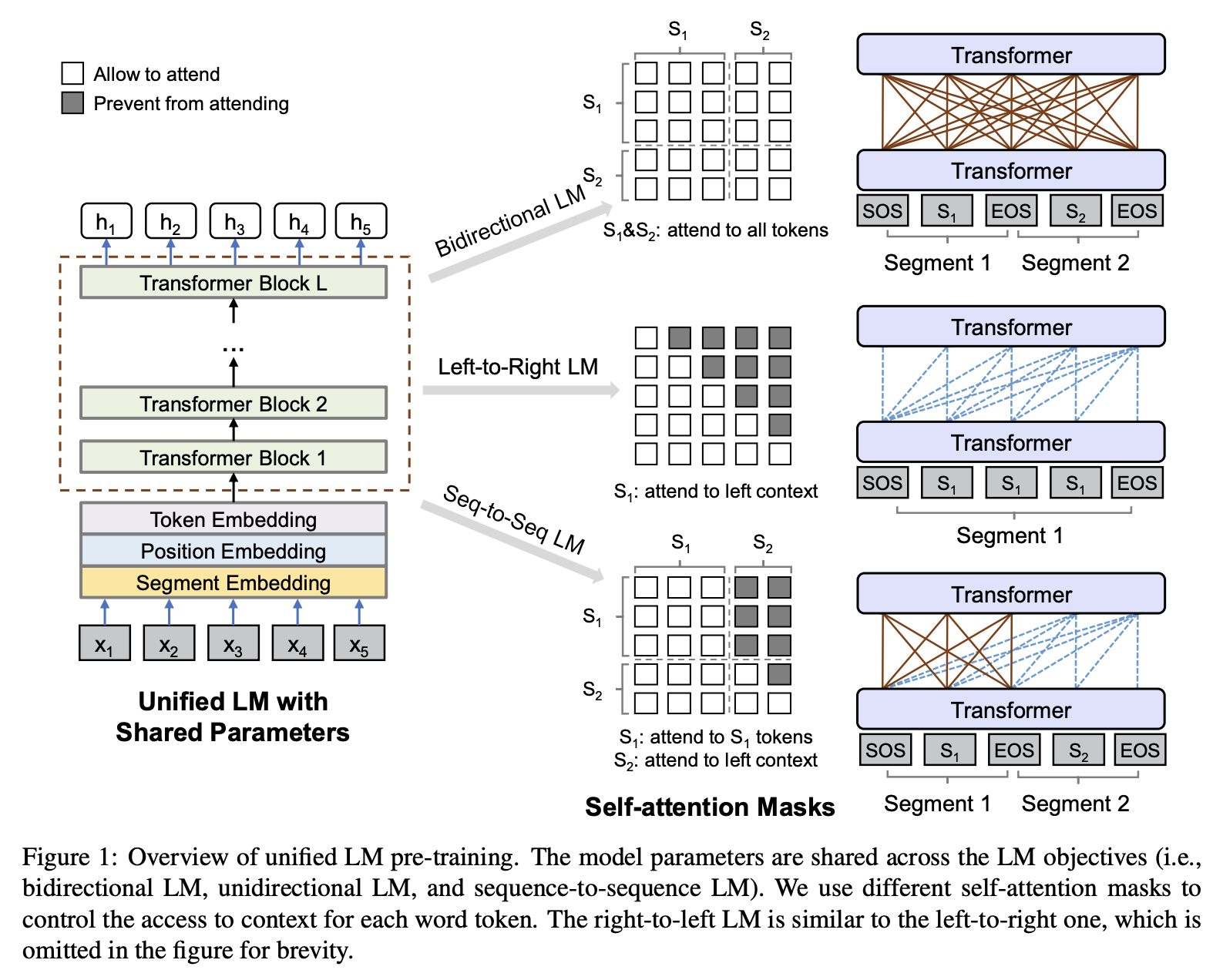
以上图为例,作者提出了三种语言模型,其实是以 mask 为实现的核心。双向 LM 就是 bert 的结构,单向 LM 是一个彻底生成模型。 而第三种 seq2seq,s1 可以获得自身的所有信息,而 s2 可以获得 s1 的信息和s2当前位置之前的信息,这可以帮助生成的内容更具有逻辑性。
应用场景
论文中工作的意义,可以应用于什么场景。
可以直接使用在NLU和NLG任务上
总结
UNILM和MASS的目标一样,都是想统一BERT和生成式模型,但我个人认为UNILM更加优雅。首先UNILM的统一方法更加简洁,从mask矩阵的角度出发改进,而MASS还是把BERT往Seq2Seq的结构改了,再做其他任务时只会用到encoder,不像UNILM一个结构做所有事情。UNILM给出了较多的结果,尤其是生成式问答有巨大的提升,而且也保证了总体效果和BERT相当,而MASS没有太注重自己的encoder。
然而UNILM和MASS没有做相同的实验,无法直接对比,个人觉得在简单些的生成式任务中可以用UNILM,但较难的翻译任务,尤其是缺少训练语料的情况下,MASS应该更合适。
参考
一些参考文献或者链接
https://www.cnblogs.com/gczr/p/12113434.html
https://medium.com/saarthi-ai/xlnet-the-permutation-language-model-b30f5b4e3c1e
Unified Language Model Pre-training for Natural Language Understanding and Generation