All NLP Tasks Are Generation Tasks:A General Pretraining Framework
基本信息
标题、时间、会议、领域、code、paper 链接
GLM 于 2021 年发表于 arxiv / code 上,论文提出了一种新的通用语言模型 GLM(General Language Model)。 GLM,使用自回归填空目标进行预训练,可以针对各种自然语言理解和生成任务进行微调。
创新点
概述
这篇论文中是解决了一个新问题,还是用一个新的方法解决了一个传统问题;创新点在哪里,有什么贡献。
现有的预训练任务大致可以分为三类:
- 自回归模型(augoregressive models),比如 GPT 这种从左向右的语言模型。
- GPT 在长文本生成方面有非常好的效果,并且参数在扩大到十亿级别后,依然保持了很强的小样本学习能力。
- 由于 gpt 使用单向注意力机制,其不能捕捉到内容上下文之间的内部联系。
- 自编码任务(autoencoding models), 比如 BERT 这种只有 encode 的任务。
- 由于多层 encode 中双向信息的流通,BERT 在内容理解方面表现优秀。
- 但不能直接应用于生成任务。
- 编码器解码器任务(Encoder-decoder) 模型在 encoder 阶段使用双向 attention 机制,在 decoder 阶段使用单向的 attention,并使用 cross-attention 将两者联系起来。
- 在有条件生成任务,如文本摘要和回复生成方面有较大优势。
- 不太好用于 内容理解方面 和 无条件生成(我理解比如长文本生成)

没有一种模型可以同时在所有 NLP 表现的好。
基于以上原因,论文提出了一个自回归空格填空的预训练任务,将其称作 GLM(General Language Model)。通过从输入文本中随机抹去连续的字符,设计自回归预训练任务。 让其可以通过学习其他的字符,进而恢复出抹去连续字符。
这个任务其实和 MLM 非常像,都是进行 token mask,但 MLM 每个字符 mask 后 对应一个 [mask] 的标志。 而 GLM 相当于所有连续字符 mask 后,只留下一个 [mask] 位置,模型其实不知道这个位置究竟有多长,从而完成一个较短的生成任务。
解决方法
具体如何实现的
预训练任务

1、对于原始文本 [x1,x2,x3,x4,x5,x6] 随机进行连续 mask,我们这里 mask 掉 x3 和 [x5,x6]。
2、将 x3 和 [x5,x6] 替换为 [MASK] 标志,并打乱 part B 的顺序。
3、GLM 尝试自回归生成 part B ,即 GLM 的输入是 part A,产出是 part B。 每个 span 以 start 开始, end 结束。
4、attention mask, part A 只能看到 part A,看不到 part B 部分。 part B 可以看到 part A,也可以看到自己的部分。
下游任务
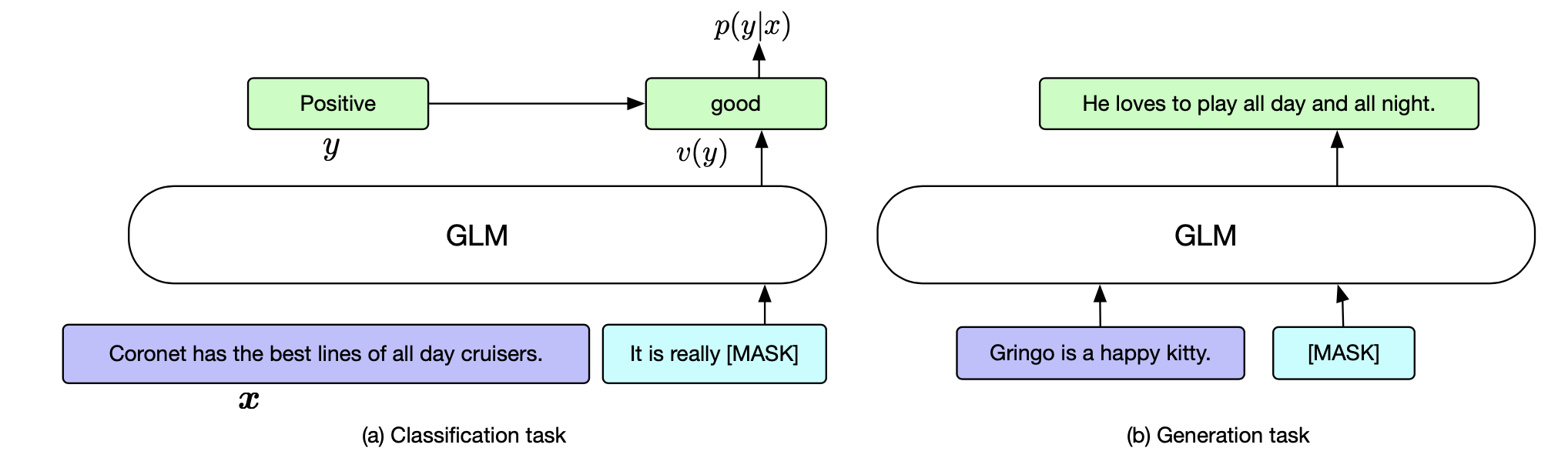
对于分类任务,可以使用 QA 的形式,判断概率,从而实现分类。
对于生成任务,partB 部分直接换成 mask 即可。
应用场景
论文中工作的意义,可以应用于什么场景。
因为模型的 part B 部分是一个生成任务,可以用于分类任务,和生成任务中。
我理解 对于文本理解类任务来说,可以直接不管 part B, 直接用 part A 部分产出的 embedding 进行类似 bert 的任务。
总结
作者总结
作者对自己成果的总结
GLM 是用于自然语言理解、生成和 seq2seq 的通用预训练框架。 我们表明 NLU 任务可以制定为条件生成任务,因此可以通过自回归模型解决。 GLM 将不同任务的预训练目标统一为自回归空白填充,混合注意掩码和新颖的 2D 位置编码。
根据经验,我们表明 GLM 在 NLU 任务方面优于以前的方法,并且可以有效地共享不同任务的参数。 未来,我们希望将 GLM 扩展到更大的 Transformer 模型和更多的预训练数据,并在更多设置(例如知识探测和小样本学习)中检查其性能。
亮点
1、将 span token 进行 mask ,将多个位置替换为 mask 标志。 然后将原句内容作为 part A,mask 掉的内容作为 part B 。从而迫使模型学到更深层次的内容, 与原始的 MLM 任务比,直觉上的确觉得有道理。
2、论文给出了代码 和 模型,相关实验也很充分,从数据上看比常见的 BERT、 T5、BART 等效果要好。
不足
1、从代码上看预训练任务的 model ,似乎就是一个 transformer 结构,但只有 train 部分,没有预测的代码。
2、这里怎么就出现了论文内的 mask 形状了呢,我似乎没算出来… 找到了,似乎在这个位置。
参考
一些参考文献或者链接
All NLP Tasks Are Generation Tasks:A General Pretraining Framework