T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
基本信息
标题、时间、会议、领域、code、paper 链接
站在 2023 这个时间点看 T5 这篇论文感觉五味杂成,T5 和 gpt2 多么像的技术方案,最终 gpt 引爆了 LLM 。
2020 年 Google 发表了 T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 这篇论文。
代码:T5: Text-To-Text Transfer Transformer、huggingface 上也有相关的代码
论文:https://arxiv.org/pdf/1910.10683.pdf
模型使用了比较标准的 seq-seq 的 transformer 结构,并且进行了非常多的有监督与训练和无监督与训练,实现了一个看起来像是 zero-shot 的结果。
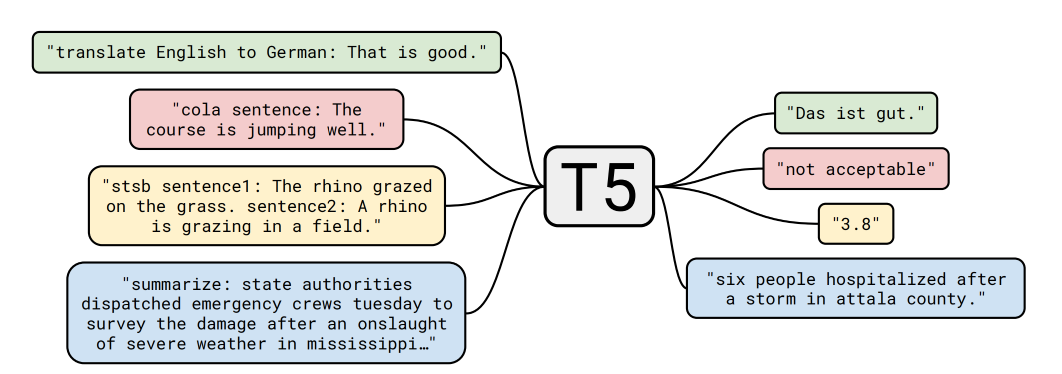
创新点
模型结构
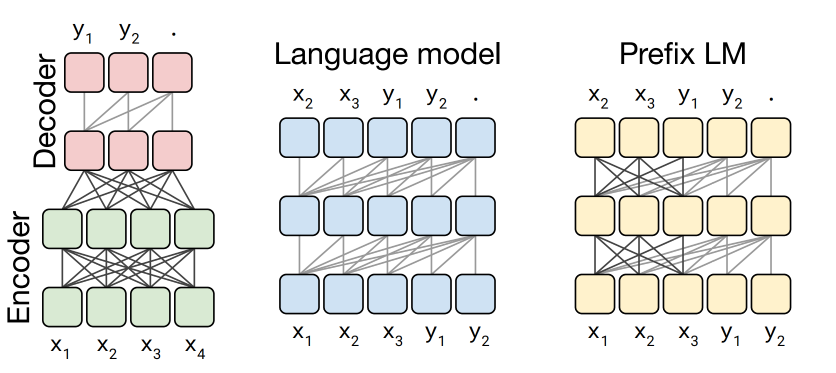
| 3 种生成架构 | 描述 | 代表模型 | 场景 |
|---|---|---|---|
| Encoder-Decoder | encoder 进行理解后,进行 decoder 生成。 | Transformer | 翻译 |
| LM | 纯生成式,前边的文字永远看不到后边的文字。 | GPT2 | 对话 |
| Prefix LM | encoder 和 decoder 的结合,部分内容可以全部看到的,部分内容只能看到过去的信息。 | unilm | 生成和理解的一种均衡 |
对于标准的语言模型 Language Model 来说,是使用前边的词来预测未来的词。 因为纯 decoder 是一个语言模型。
控制视野的抓手就是 attention mask,对于 encoder 来说一般使用如下图左侧的结构,对于 decoder 来说为下图中的结构。 Prefix 结构主要考虑为控制视野,Encoder 和 Decoder 的结合体。

作者们发现 Text-Text 这个场景上,Encoder-Decoder 效果最好。
训练方法
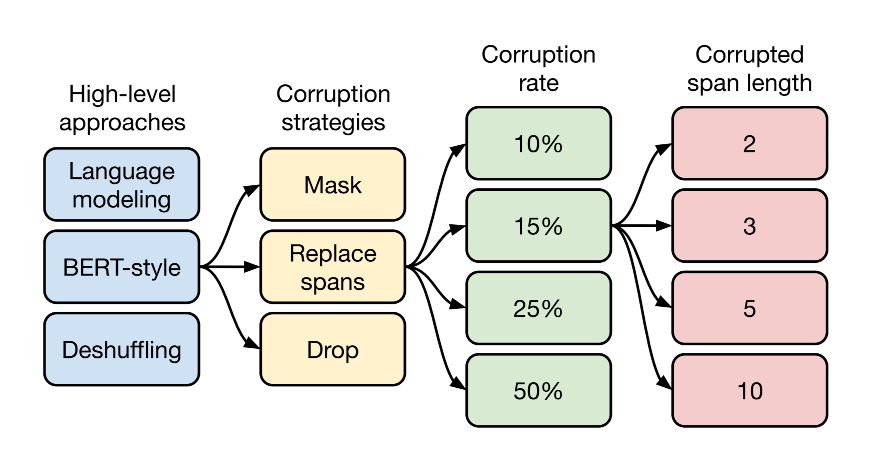
第一个方面,高层次方法(自监督的预训练方法)对比,总共三种方式。
- 语言模型式,就是 GPT-2 那种方式,从左到右预测;
- BERT-style 式,就是像 BERT 一样将一部分给破坏掉,然后还原出来;
- Deshuffling (顺序还原)式,就是将文本打乱,然后还原出来。
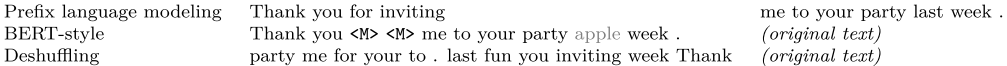
其中发现 Bert-style 最好。
第二方面,对文本一部分进行破坏时的策略,也分三种方法。
- Mask 法,如现在大多模型的做法,将被破坏 token 换成特殊符如 [M];
- replace span(小段替换)法,可以把它当作是把上面 Mask 法中相邻 [M] 都合成了一个特殊符,每一小段替换一个特殊符,提高计算效率;
- Drop 法,没有替换操作,直接随机丢弃一些字符。
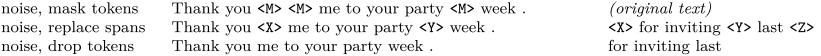
发现 Replace Span 法最好,类似做法如 SpanBERT 也证明了有效性。
第三方面,到底该对文本百分之多少进行破坏呢,挑了 4 个值,10%,15%,25%,50%,最后发现 BERT 的 15% 就很 ok了。这时不得不感叹 BERT 作者 Devlin 这个技术老司机直觉的厉害。
第四方面,因为 Replace Span 需要决定对大概多长的小段进行破坏,于是对不同长度进行探索,2,3,5,10 这四个值,最后发现 3 结果最好。
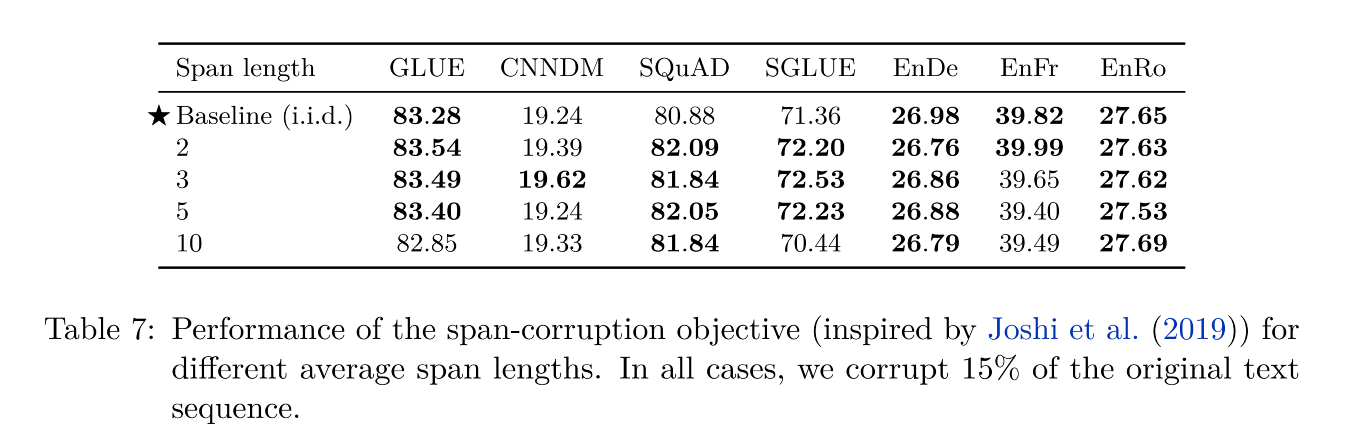
数据处理
使用到了一个新的 relative position embedding,T5使用了简化的相对位置embeding,即每个位置对应一个数值而不是向量,将相对位置的数值加在attention softmax之前的logits上,每个head的有自己的PE,所有的层共享一套PE。个人认为这种方式更好一点,直接在计算attention weight的时候加入位置信息,而且每一层都加一次,让模型对位置更加敏感。
其中关键的函数是_relative_position_bucket 这里有一篇文章来详细介绍, https://zhuanlan.zhihu.com/p/444438914。
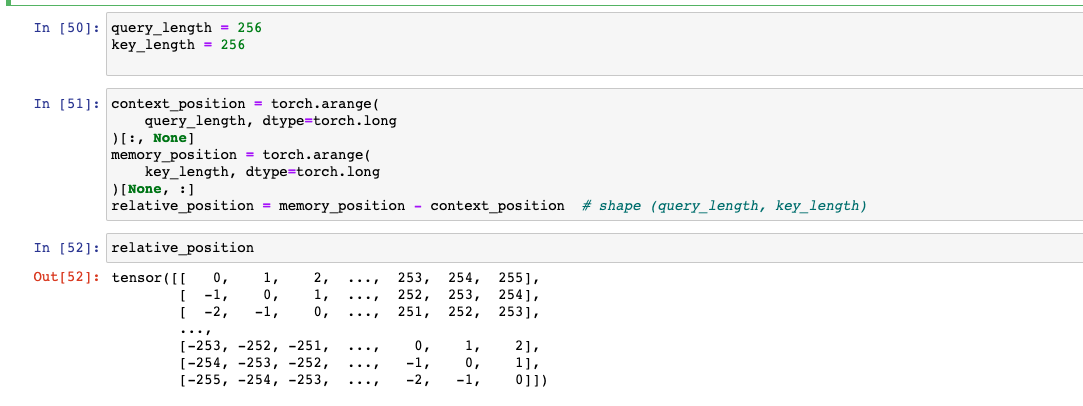
我们先构造出 relative_position,可以看出来是一个[-255,0] 和 [0,255]的滑动数字。


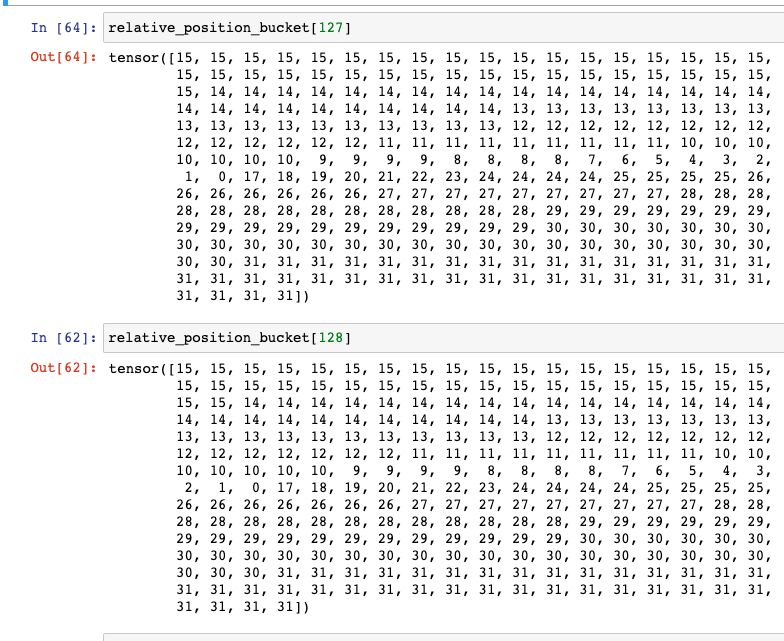
这边来看一下结果,从当前位置0开始,左边为 [1,15] ,右边为 [16,31]。
这些 id 会去 position_embedding 表中取出 embedding 来:
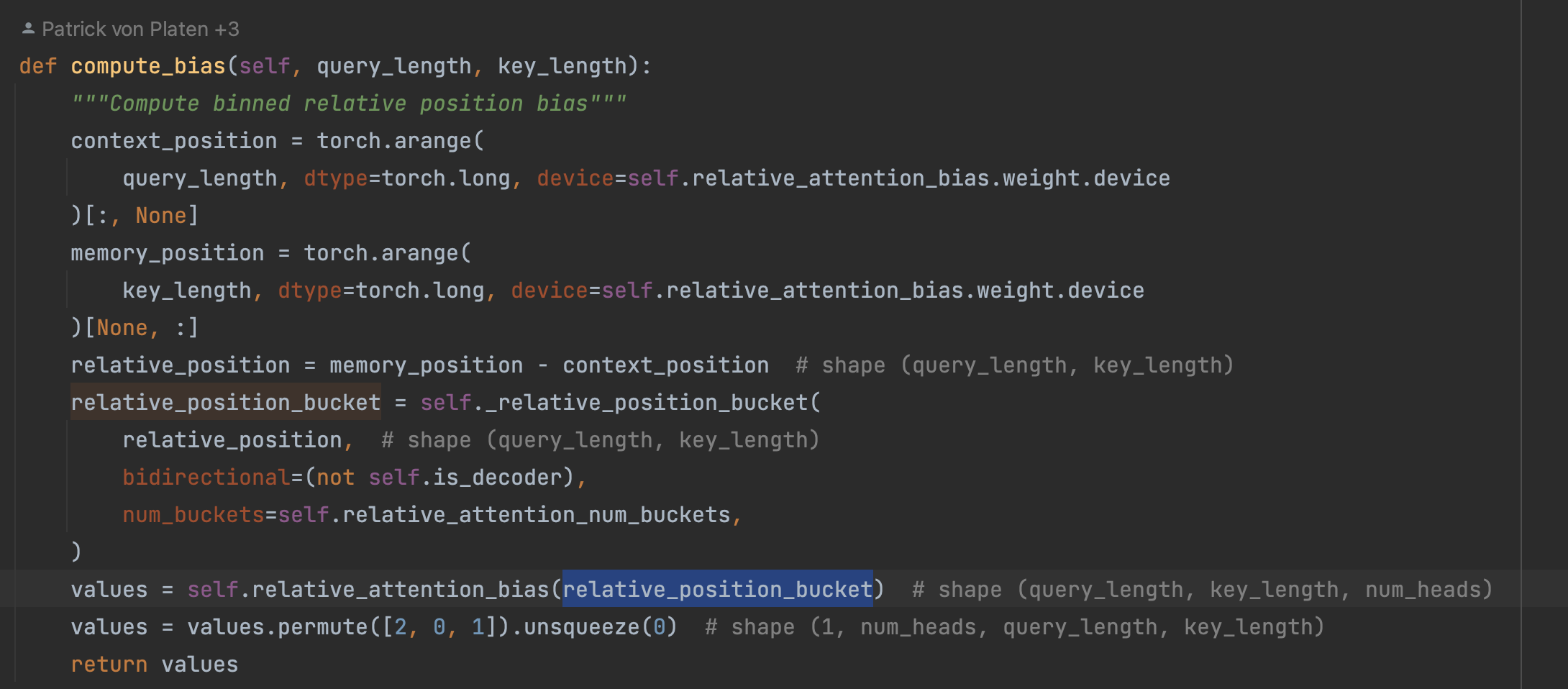
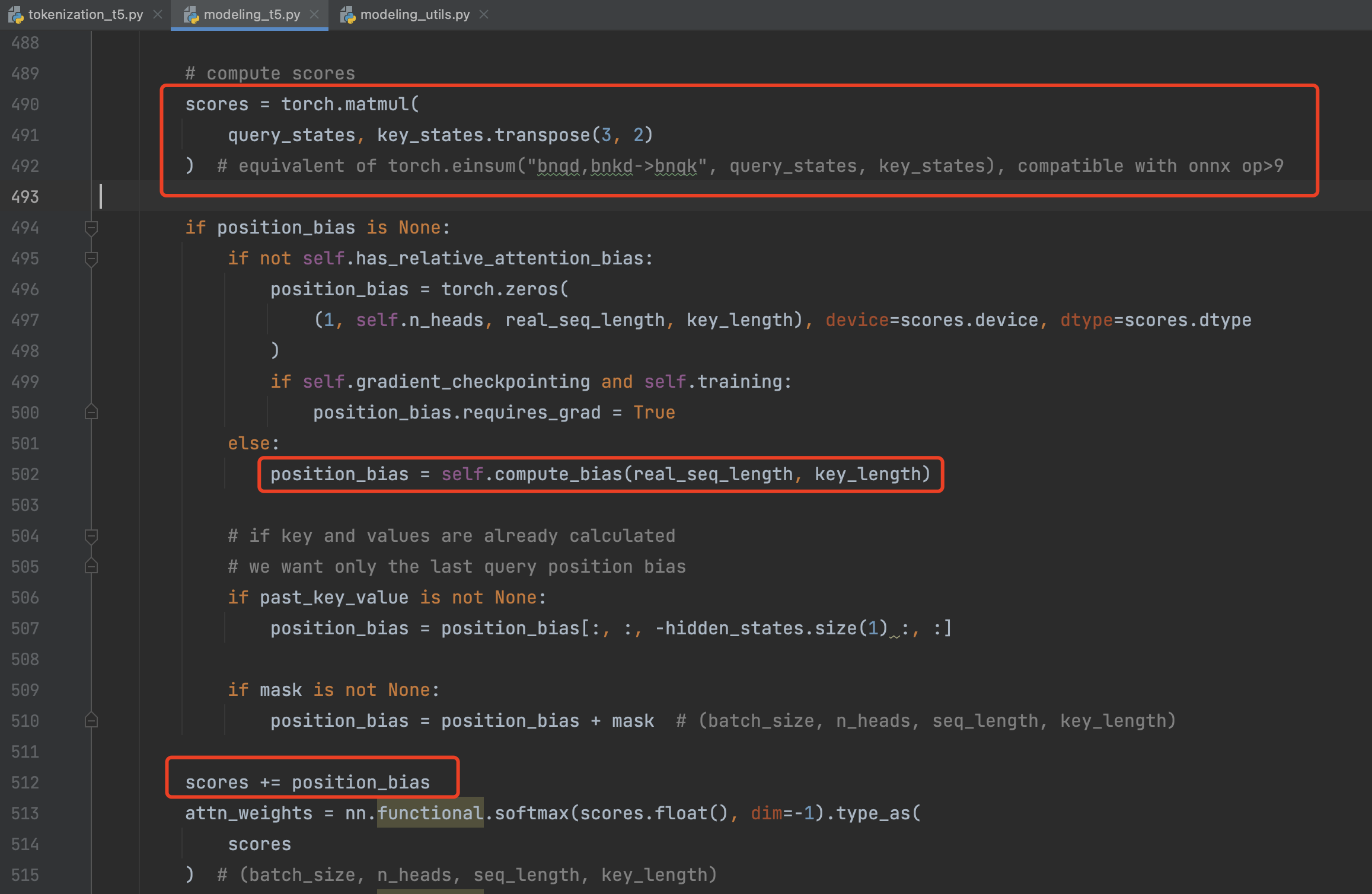
将这个 embedding 与 q * k 的结果相加,这里很特别。bert 是在 input_embedding 那里进行进行想加,这里是每一层都强化认知。
总结
T5 模型的成功一部分来源于夸张的参数量和数据集,以及合适的调参、数据集过滤等策略。而能实现这样大规模实验的关键思想在于,text-to-text 框架对各项 NLP 任务和相关数据的整合。
T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer