GPT GPT2 GPT3 系列论文
基本信息
Github:https://github.com/openai/gpt-2 、https://github.com/openai/gpt-3
GPT 系列是历史非常悠久的论文了,gpt1 甚至在 bert 之前就发布了。 但在下游任务上的表现,并没有 bert 亮眼,所以一直默默无闻。最近 chatgpt 大火,又把 gpt 的论文翻出来复习一下。
GPT系列
Transformer
Transformer 是一个标准的 encode-decode 的结果, 其中,encode 和 decode 的结果非常类似。
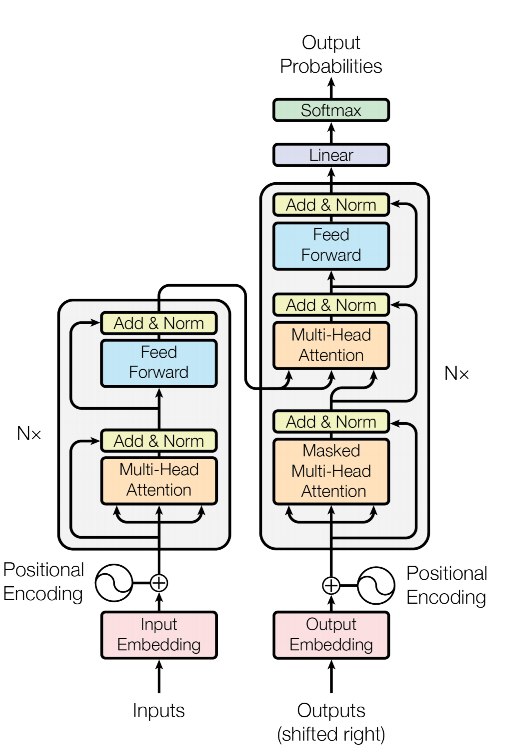
encode部分单独剥离出来,成为了 bert。 而 decode 部分被单独拿了出来,成为了 gpt。
GPT1
预训练任务
gpt1 有两个预训练任务,分别为:
- 无监督训练的语言模型
gpt1 是一个标准的语言模型,即:模型在知道前边字的情况下,来预测当前的字, k 就是上下文窗口。

- 有监督的分类任务

上述两个任务是在同时训练的,有一个权重来调节两者的比例。
任务 task
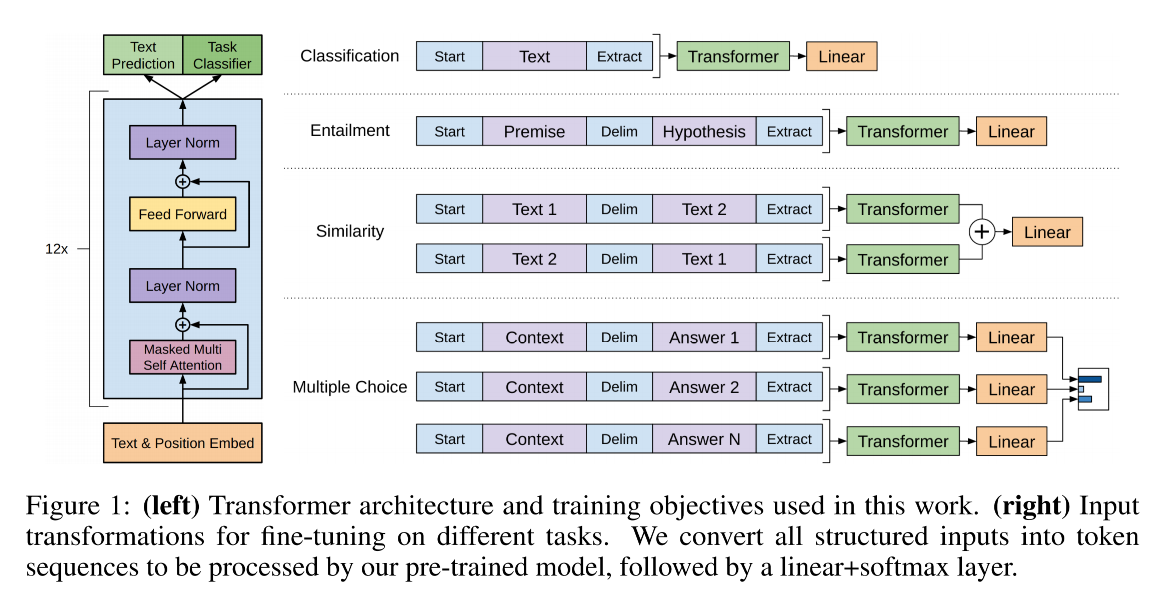
那如果要用的话,该怎么用呢,论文中给出了 4 种下游任务的数据构造方式(分类、推理、相似、多分类)
小结
1、从如下对比中可以看出来, bert 还是有一些巧思的。
- gpt 和 bert base 是一样大的,考虑到 bert 要晚于 gpt 出现,bert 有明显对标 gpt 的嫌疑。
- 在无监督任务方面,bert 采用上下文预测当前字的任务,要明显易于 gpt 的根据上文预测下文的任务。
- 在有监督任务方面, bert 采用了一个自监督任务(上下文预测),gpt 使用了分类任务。
2、fine-tune 只能使用到特定的任务中,分类任务中 fine-tune 的模型不能使用到句子相似度中来。 这一点就成为了后续 gpt2 的优化点了。
GPT2
idea
gpt1 是作为一个 backbone model 而存在的,在具体的任务中需要进行 finetune,这跟 bert 的使用方式是类似的。
作者认为,当一个语言模型的容量足够大时,他就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集。
比如语料中可能就存在 英文<—>法文 内容:

那么模型就应该很自然的学会了英文法文翻译。
gpt2 的核心思想为:任何有监督的任务都是语言模型的一个子集,当模型的容量非常大且语料足够丰富时,仅仅靠训练语言模型就可以完成其他有监督学习的任务。
也就是模型变成了 p(output|intput,task),此时是一个 zero-shot 的情况了。
数据
使用了 Reddit 上赞同数较高的链接内的内容,命名为 WebText。
总结
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。尽管在有些zero-shot的任务上的表现不错,但是我们仍不清楚GPT-2的这种策略究竟能做成什么样子。GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了我们下面要介绍的GPT-3。
GPT3
gpt2 提出了的方法应该算是 zero-shot,这种任务是比较难的。仅仅靠几个词,模型并不容易理解任务。
In-context learning
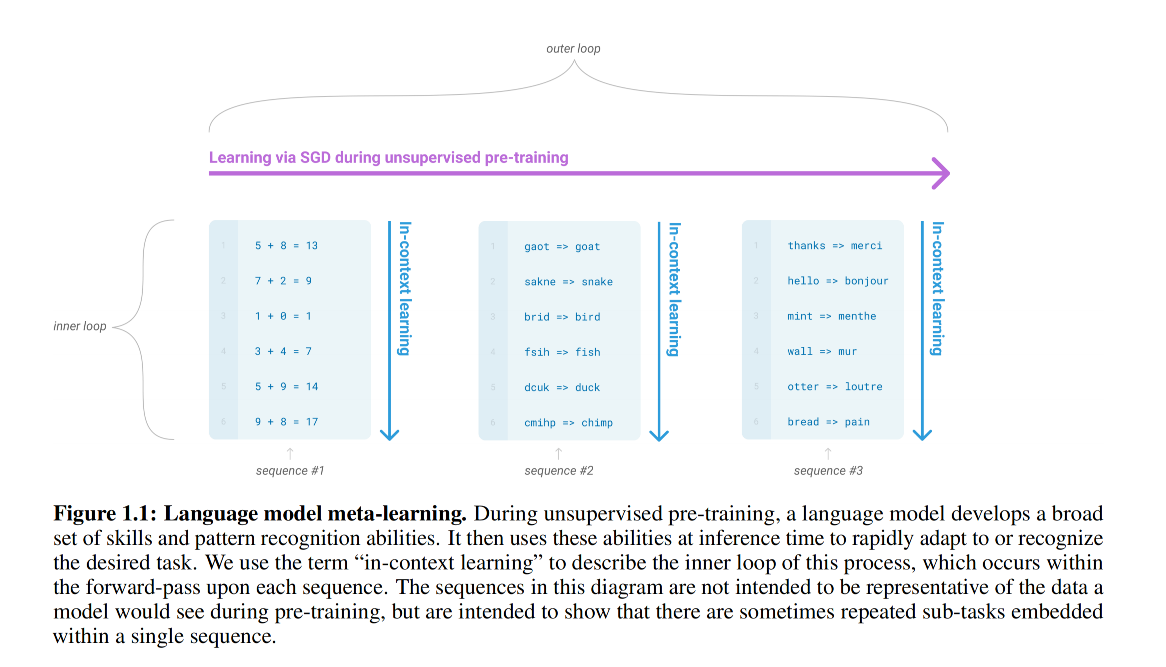
对一个网络模型 $f$ ,其参数表示为 $\theta$,它的初始化值被叫做meta-initialization。
直观的理解,我用一组meta-initialization去学习多个任务,如果每个任务都学得比较好,则说明这组meta-initialization是一个不错的初始化值,否则我们就去对这组值进行更新,如图4所示。目前的实验结果表明元学习距离学习一个通用的词向量模型还是有很多工作要做的。
Few-shot,one-shot,zero-shot learning
few-shot learning中,提供若干个( 10 - 100 个)示例和任务描述供模型学习。
one-shot laerning是提供1个示例和任务描述。
zero-shot则是不提供示例,只是在测试时提供任务相关的具体描述。
作者对这3种学习方式分别进行了实验,实验结果表明,三个学习方式的效果都会随着模型容量的上升而上升,且 few shot > one shot > zero show,这个过程也是符合预期的。


区别
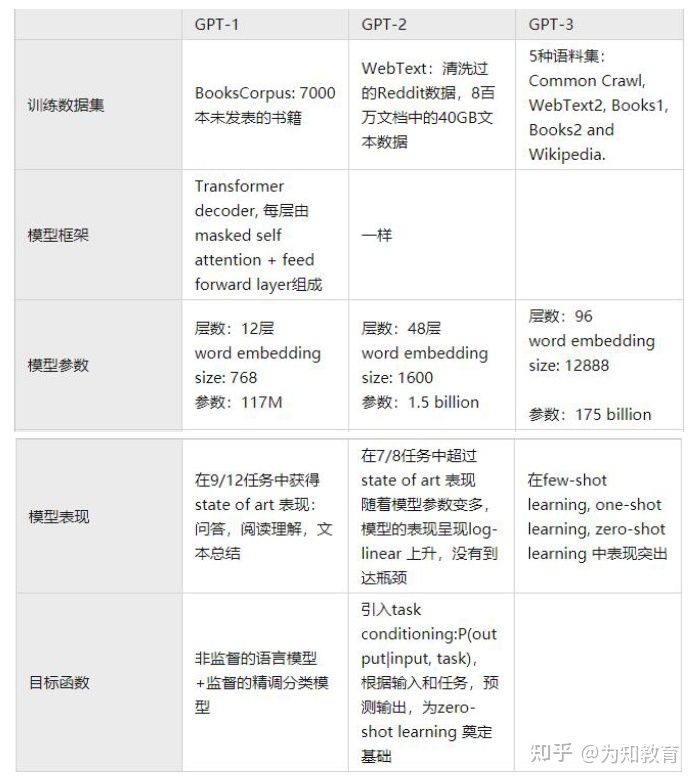
GPT GPT2 GPT3 系列论文