pytorch 实现 bert,附带详细的注释和 transformers 国内下载链接
简介
Bert 是 NLP 领域(甚至是在 DL 领域)最近几年最重要的论文了,其将预训练任务、 attention 发扬光大,开辟了一个非常有趣的研究放方向,甚至后续的很多 cv 网络中(如 vit、 vilbert、mae)都可以看到它的身影。

使用纯 pytorch 实现(无 transformers 等多余依赖): backbone_bert
代码实现
bert 的结构并不复杂,但对于刚入门的同学来说,理解起来还是有一点点麻烦的,我们先拿出 transormer 的结构图来。
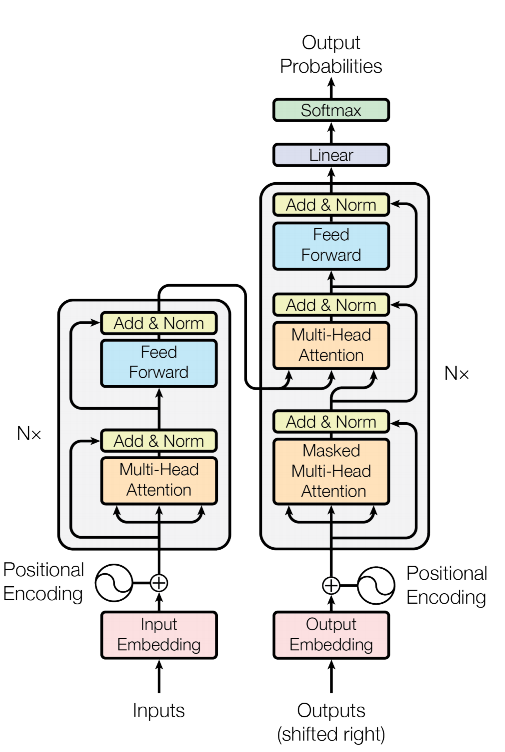
bert 只使用了 transformer 的 encoder 部分,也就是下边这一部分。
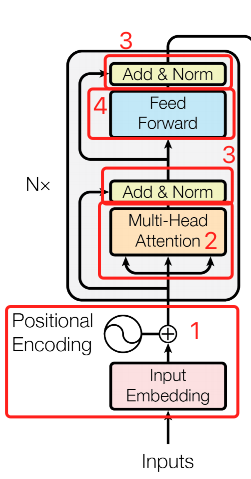
1、Bert Embedding

对照上边的图,我们先实现第一部分,也就是 input_embedding 和 postional_embedding 的部分。
input_embedding和segment_embedding是随机初始化得到的;postinal_embedding可以通过初始化得到,也可以通过sin_cos的方式得到,效果差不多;- 在
transformer中,segment_id也被称作type_id,input_id也被称作token_id,都一回事; - 代码实现参考 bert_layer.py#L17-L64了;
大家可能会看到这里的 LayerNorm 比较特别,是自己实现的 layer_norm 代码,这块其实结果和 torch.nn.LayerNorm 是没有区别的。但是在效率上,torch.nn.LayerNorm 速度更快一些,可能是 torch 自己做了一个额外的优化导致。
题外话,需要注意 LayerNorm 和 BatchNorm 的区别,面试的时候我经常问 😂 。 LayerNorm 是对每一条数据进行 Norm,而不是每一批数据,这两个很像,但作用纬度不一样。在 NLP 任务中,我们使用 LayerNorm 比较多,因为是:
- 文本自身是变长的,max_length 为 512 的话,可能大部分的数据都只有几十个字。那么让这几十个字以及大批的 padding 进行 norm 是不合理的。
- batchNorm 中的 平均值 和 方差,是在训练任务中学到的。 然后推理的时候,根据训练任务中学到的平均值和方法来使用,比如 cv 中常见的 transforms.Normalize。如果使用 LayerNorm 的话,就不需要提前计算好平均值和方法,每句话输入进来的时候,单独计算就可以了。对于变长文本预测来说,这样其实更合理一些。
- 自己实现 layerNorm 还可以方便后续进行一些细小的优化。可参考 https://iii.run/archives/7bc07ace1d70.html 。
2、Multi-Head Attention
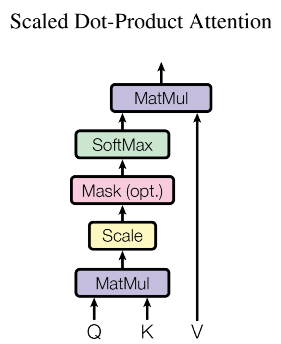
接下来,我们实现第二个部分 Multi-Head Attention 多头注意力机制,我们先看单纯的 点积Attention 结构。
这一部分的代码比较长,可以直接参考 bert_layer.py#L67-L190,基本上都有注释。 我们知道,多头注意力中每个头可以注意到不同的内容,需要实现一个高效的多头机制。而对纬度直接进行调整,从而得到多个头的方式非常高效。
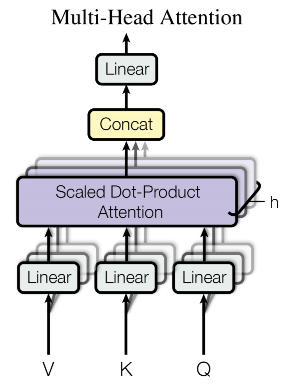
也就是这里的实现
1 | def transpose_for_scores(self, x): |
在 q*k 的时候,num_attention_heads 应该是不感知的,所以需要将 num_attention_heads 调整到第二个纬度上来。

自此就实现了 Scaled Dot-Product Attention 的部分。
3、Add & Norm
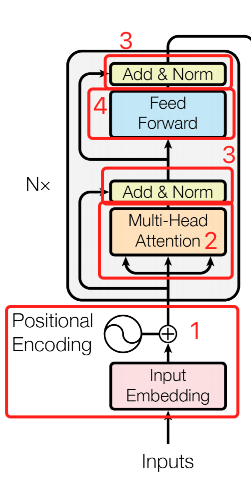
「Add & Norm」 部分的代码实现,可以直接参考 bert_layer.py#L193-L215 ,在 bert 中会循环多次使用,这里我将原始的 BertSelfOutput 和 BertOutput 和成一个了,这里的 Add & Norm 实现了三个功能:
- 在
Multi-Head attention后,所有的头注意力结果是直接concat在一起的( view 调整 size 也可以认为 concat 在一起)直接 concat 在一起的结果用起来也有点奇怪,所以需要有个 fc ,来帮助把这些分散注意力结果合并在一起; - 在
Feed Forward操作后,纬度被提升到intermediate_size,BertAddNorm还实现了把纬度从intermediate_size降回hidden_size的功能;一般来说,intermediate_size是hidden_size的 4倍大小,非常像卷积核大小为 1 & 多个卷积核 时的情况,都是对原始输入进行放大然后再缩小,我认为可以更好的关注的输入内容的不同角度。 但BertAddNorm这里的实现要比卷积操作高效很多。 - 真正的
Add & Norm部分,也就是layer_norm(hidden_states + input_tensor)这一行,也就是这里的代码有多实现dense和dropout后边会有说明;
1 | class BertAddNorm(nn.Module): |
4、Feed Forward
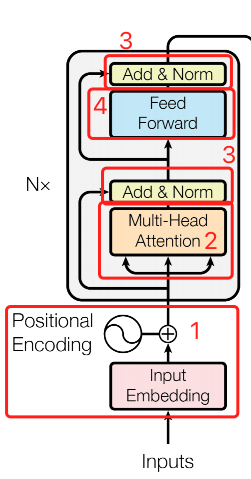
「Position-wise Feed-Forward Networks 」 的代码实现,来自于 bert_layer.py#L218-L237

1 | class BertIntermediate(nn.Module): |
大家可能会发现,诶? 这里怎么只有 FFN 的左半部分,外边的那个 dense 呢? 外边的那个 dense 在 Add&Norm 里边了,其实我觉得这块不太合理的,但不太好修改结构,因为修改了结构原始的参数就加载不上了。
5、Bert Layer
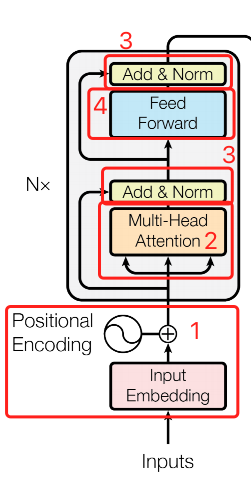
至此,我们可以组装出 2+3 部分,也就是 N* 循环内的下半部分,bert_layer.py#L240-L263
1 | class BertAttention(nn.Module): |
并进一步得到完整的一个 bert_layer,bert_layer.py#L266-L289
1 | class BertLayer(nn.Module): |
6、Bert Encoder
将 Bert Layer 的结果,循环num_hidden_layers次,将上一轮的输出,输入到新的一轮中,代码实现 bert_model.py#L18-L52
7、Bert Pooler
对于 CLS 位,我们会进行一个特殊的 pooler 操作,即 bert_model.py#L55-L66,所以我们直接取 cls 位的结果,并不是真的第一个位置上的 embedding,而且该 embedding 经过变形并激活后的结果。
1 | class BertPooler(nn.Module): |
8、Bert Module
这里基本上就是进行一系列合并,将 Bert Embedding 的结果输入到 BertEncoder中,具体实现 bert_model.py#L69-L185
需要注意的是,key 的替代操作,这里是因为 tf 的权重和 pytorch 权重的名称不太一样,特别是 layer_norm 的,tf 中的命名感觉不太规范,将对象命名成为了大驼峰,所以不 replace 的话就无法加载进来了。
总结
1、安装库
pip install pure_attention==0.0.20 或者 git clone link 到本地
2、下载预训练模型
这里我弄了 transformers国内下载镜像,关于 lfs,可以参考 git lfs 。
| 模型名称 | git clone | 自行下载 |
|---|---|---|
| bert-base-chinese | git clone git@e.coding.net:mmmwhy/file/bert-base-chinese.git |
https://mmmwhy.coding.net/public/file/bert-base-chinese/git/files |
| chinese-roberta-wwm-ext | git clone git@e.coding.net:mmmwhy/file/chinese-roberta-wwm-ext.git |
https://mmmwhy.coding.net/public/file/chinese-roberta-wwm-ext/git/files |
| chinese-roberta-wwm-ext-large | git lfs clone git@e.coding.net:mmmwhy/file/chinese-roberta-wwm-ext-large.git |
https://mmmwhy.coding.net/public/file/chinese-roberta-wwm-ext-large/git/files |
| ernie 1.0 | git clone git@e.coding.net:mmmwhy/file/ernie-1.0.git |
https://mmmwhy.coding.net/public/file/ernie-1.0/git/files |
速度还是比较可观的,
3、使用 demo
1 | from pure_attention.common.nlp.tokenization import Tokenizer |
4、一致性校验
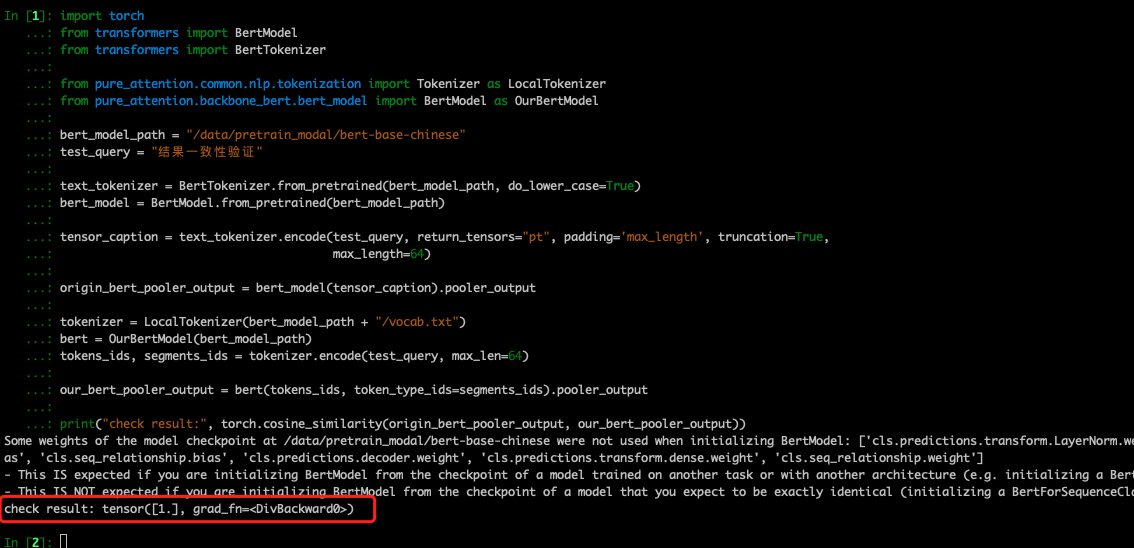
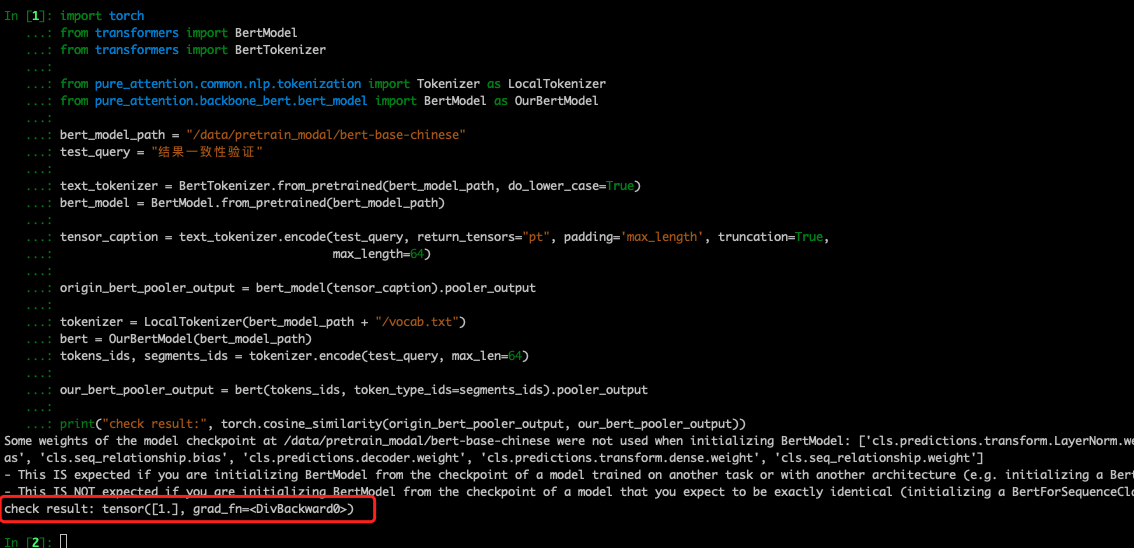
在 4 种常见中文 bert 上进行实验,结果与 transformers 完全一致。校验代码
1 | import torch |
当时截图的时候比较早,代码稍微做了一些调整就没有新截图了,以代码为准。


5、其他部分
我一直想细致的了解一下底层代码的实现,特别是可以和 transformer 的设计图对应起来。在看了一些已有的代码后,发现 transformers 为了适应非常多种模型结构,结构变得非常复杂,代码看来比较复杂。
因此希望自己可以完成一个这样的作品,让其可以在 cv 任务和 nlp 任务上均取到 sota 的效果,我将其称之为 pure_attention 。
我在参考transformers 、 bert4pytorch 、Read_Bert_Code的代码基础上,对结构进行了一些调整,提高了代码的易读性,并和 transformers 的结果完全一致。
pytorch 实现 bert,附带详细的注释和 transformers 国内下载链接