ViT: AN IMAGE IS WORTH 16X16 WORDS :TRANSFORMERS FOR IMAGE RECOGNITION ATSCALE
背景
paper: https://arxiv.org/pdf/2010.11929.pdf
code: GitHub - google-research/vision_transformer
《AN IMAGE IS WORTH 16X16 WORDS :TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》是一篇来自于 ICLR 2021 的论文,论文尝试以 end-end transformer 的方式理解图片,并在分类任务上取得了非常好的效果,为 cv 方向挖了一个大坑,最近两年以 transfermer 的方式多次刷新了榜单,其中出现了如 mae、detr之类的好作用。

模型结构
这张图可以很清楚的说明模型的结构了,这里我进行一些补充。
Patch embedding:我们以 size 为 224 224 图片为例,一个 patch 是 16 16 ,那么一个 patch 的 参数量 16 16 3 = 768, 那么一共会得到 (224 224) / (16 16 ) = 14 14 = 196 个 patch,即进入 transformer 的矩阵为 196 768。
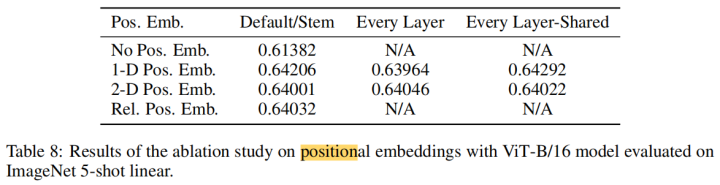
Postion embedding:论文提到了四种 embedding 方案,具体细节如下:
- 无positional embedding
- 1-D positional embedding:把2-D的patchs看成1-D序列
- 2-D positional embedding:考虑patchs的2-D位置(x, y)
- Relative positional embeddings:patchs的相对位置
1-D 也就是按 1、2、3、4、5、6、7…. 这样的位置来得到 embedding, 2-D 就是 1-1、2-1、3-1、2-1、2-2…. 诸如此类的方式,将两个维度上产出的 embedding 拼凑得到一个位置上的 position embedding,从结果上来看,除了没有 pos 会有影响,其他三个没什么区别。
CLS Token: 借鉴 bert 的分类任务,设计了一个特别的 CLS Token。transformer 的 encoder 输入是 a sequence patch embeddings,输出也是同样长度的 a sequence patch features,但图像分类最后需要获取image feature,常见的策略是进行 mean pooling,但是ViT并没有采用类似的pooling策略,而是直接增加一个特殊的class token。其最后输出的特征加一个 linear classifier 就可以实现对图像的分类(ViT的 pre-training时是接一个MLP head),所以输入ViT的sequence长度是 N+1。class token对应的embedding在训练时随机初始化。
Pretrain 任务: 使用分类任务进行 Pretrain,我觉得这个任务是非常弱的,哪怕是同样一张图片进行增强后做对比学习,感觉也比用分类任务做预训练要强,分类任务依赖有监督的数据,是很难扩量的。
效果
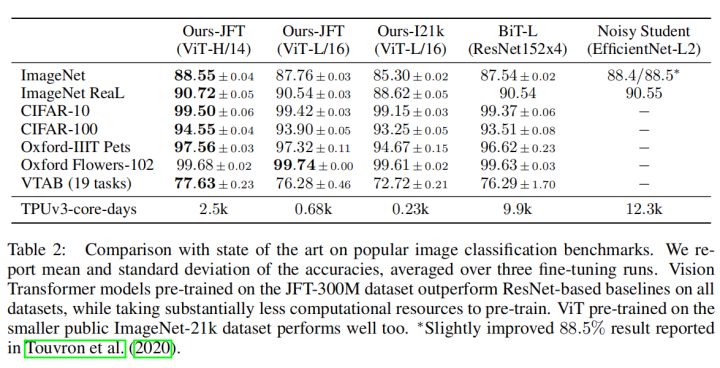
效果应该从两个方面来看,首先看指标方面,ViT 在小数据集上的效果不如 ResNet ,但是在大数据集上效果比 ResNet 好,而且随着数据量的增加,上升的趋势并没有结束,这证明可以做非常大的预训练任务。
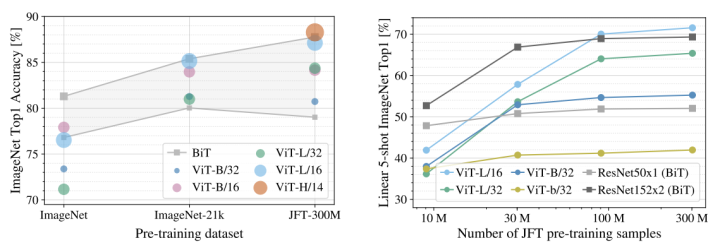
从速度上来看,同样预训练计算量的情况下,ViT 效果更好一些。

优点
- 没有使用特定的 image-specific inductive biases ,而是使用通用的 transformer 结构,真正做到了 attention is all you need!
- 训练便宜,相较于动辄上百层的 CNN , 12 层的 transformer 明显更 cheap 一些。
结语
- 在除了分类任务外的其他 cv 任务,如目标检测、语义分割上的效果不太理想。
- 我觉得可以进一步优化预训练任务,比如 MAE 这样彻底的对像素粒度进行 mask 的工作。
- ViT 处处透露着和 BERT 的相似,就比如这个模型结构。
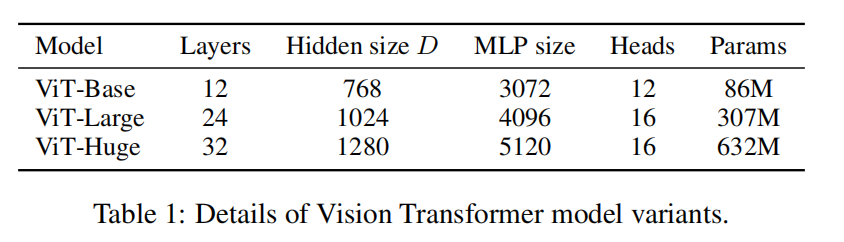
- ViT 与 VILBERT 相比,我觉得最大的贡献就是做到了 end-end,而不需要一个前置的不能训练操作进行特征块的提取,我认为这对效果的影响会非常大。
ViT: AN IMAGE IS WORTH 16X16 WORDS :TRANSFORMERS FOR IMAGE RECOGNITION ATSCALE