ERNIE-ViL:Knowledge Enhanced Vision-Language Representations Through Scene Graph
背景
论文来自于百度在2020年AAAI上提出的知识增强视觉-语言预训练模型 《ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph》,在多个比赛上获得了 SOTA 的结果。
我们在看 CLIP 的时候,可能会震惊于 4亿的训练数据 和 大量的训练资源。 过多的数据导致数据质量可能层次不齐,而大量的 GPU 资源会使复现的难度大大增加。
百度带来的这片 ERNIE-VIL 使用了 Conceptual Captions (CC) dataset 和 SBU dataset 数据集,共计 400w 左右的训练数据,以及 8 V100 GPU 的训练资源, 让多模态预训练的复现难度大幅下降。
相关研究
Oscar 是比较典型的单流结构,效果似乎很好,但我们需要比较每个 word 和 图片的关系,灵活性似乎不足。
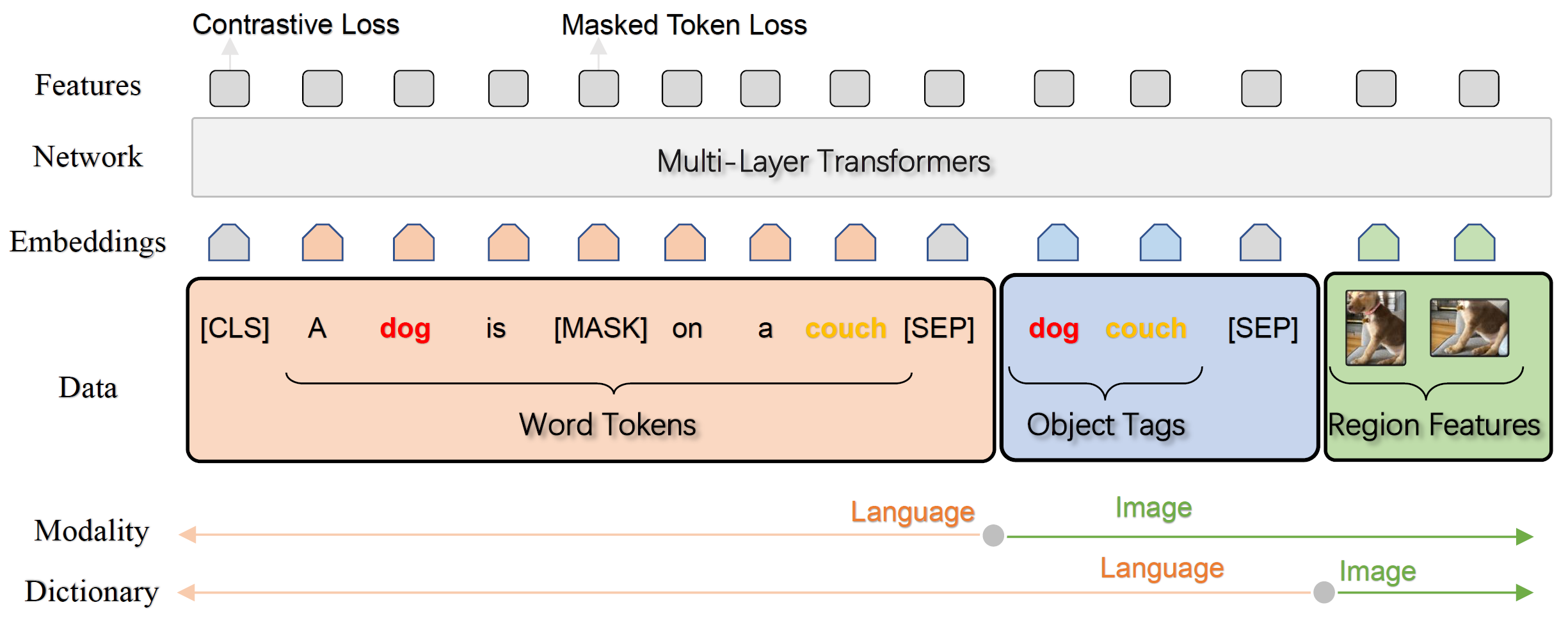
CLIP 是双塔结构,图片和文本分别走两个塔,分别产出 文本 embedding 和 图像 embedding,并基于两个 embedding。 算法结构非常好理解,其特殊的设计在于训练阶段。
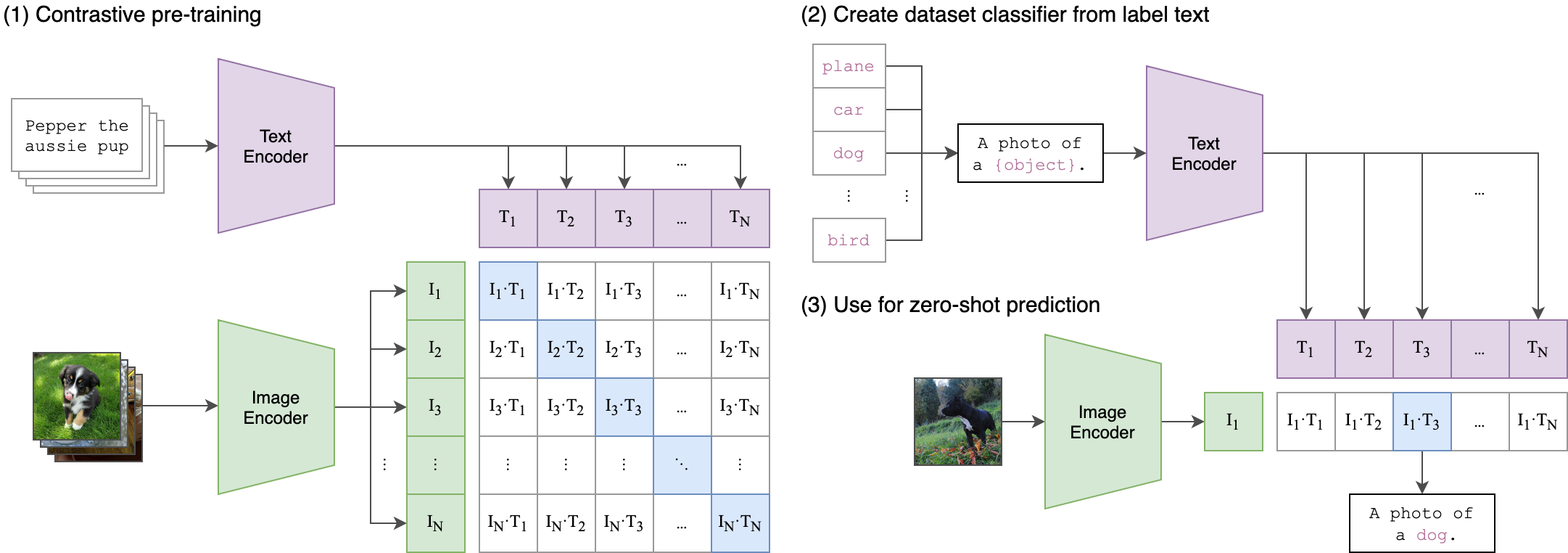
CLIP 使用了 4亿的训练数据,并且训练数据以 上图左的方式进行组合,对角线上的 ImageText 对为正样本(共 N 个),其余部分 N^2 -N 为负样本。在资源上,也大手笔的使用上百张 V100 。

关于模型的更多部分,可以参考 如何评价OpenAI最新的工作CLIP:连接文本和图像,zero shot效果堪比ResNet50? - 一只小肥羊的回答 - 知乎 https://www.zhihu.com/question/438649654/answer/1769045845。
在大量数据和计算资源的帮助下,CLIP 的确获得了非常好的收益,并且使用起来非常方便,但在训练上却非常的困难。
我们不禁提出疑惑,有没有一种方法,可以兼顾 训练和推理的效率呢。ERNIE-VIL 为我们提供了一种新的思路。
实现方法
我在看 CLIP 的时候,第一个困惑是 N^2 -N 的负样本,N 个正样本,正负样本比例会不会太悬殊了。第二个困惑是负样本的选择会不会太敷衍,为什么没有 hard sample 。
ERNIE-VIL 引入了自己的设计,我们目前也在参考 ERNIE-VIL 的方案设计自己的预训练模型。
idea
原始的 bert 采用 MLM 的方式进行模型训练,ERNIE 设计过一种 knowledge masking strategy ,mask 掉有有含义的表示部分,从而实现效果的提升。
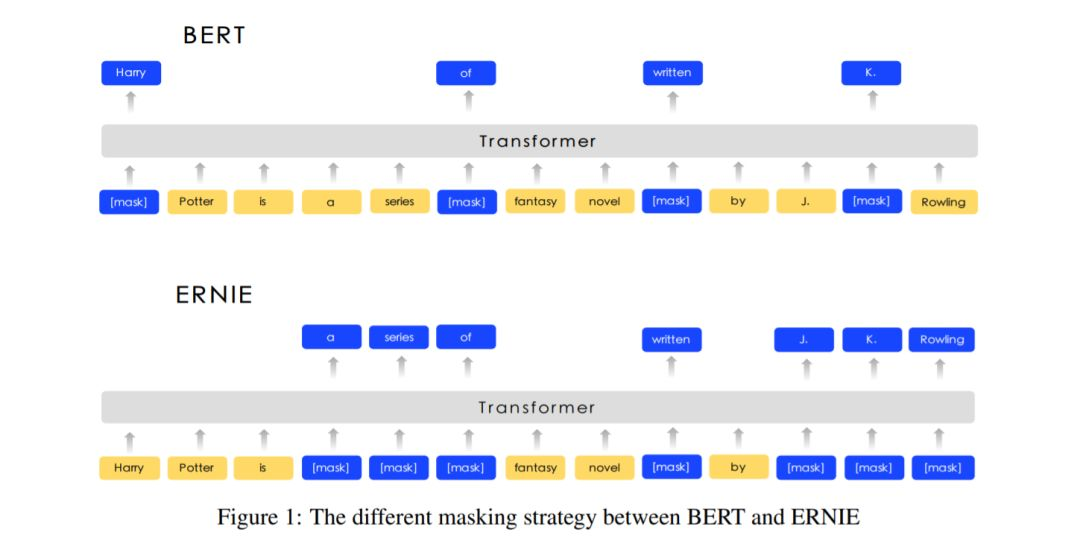
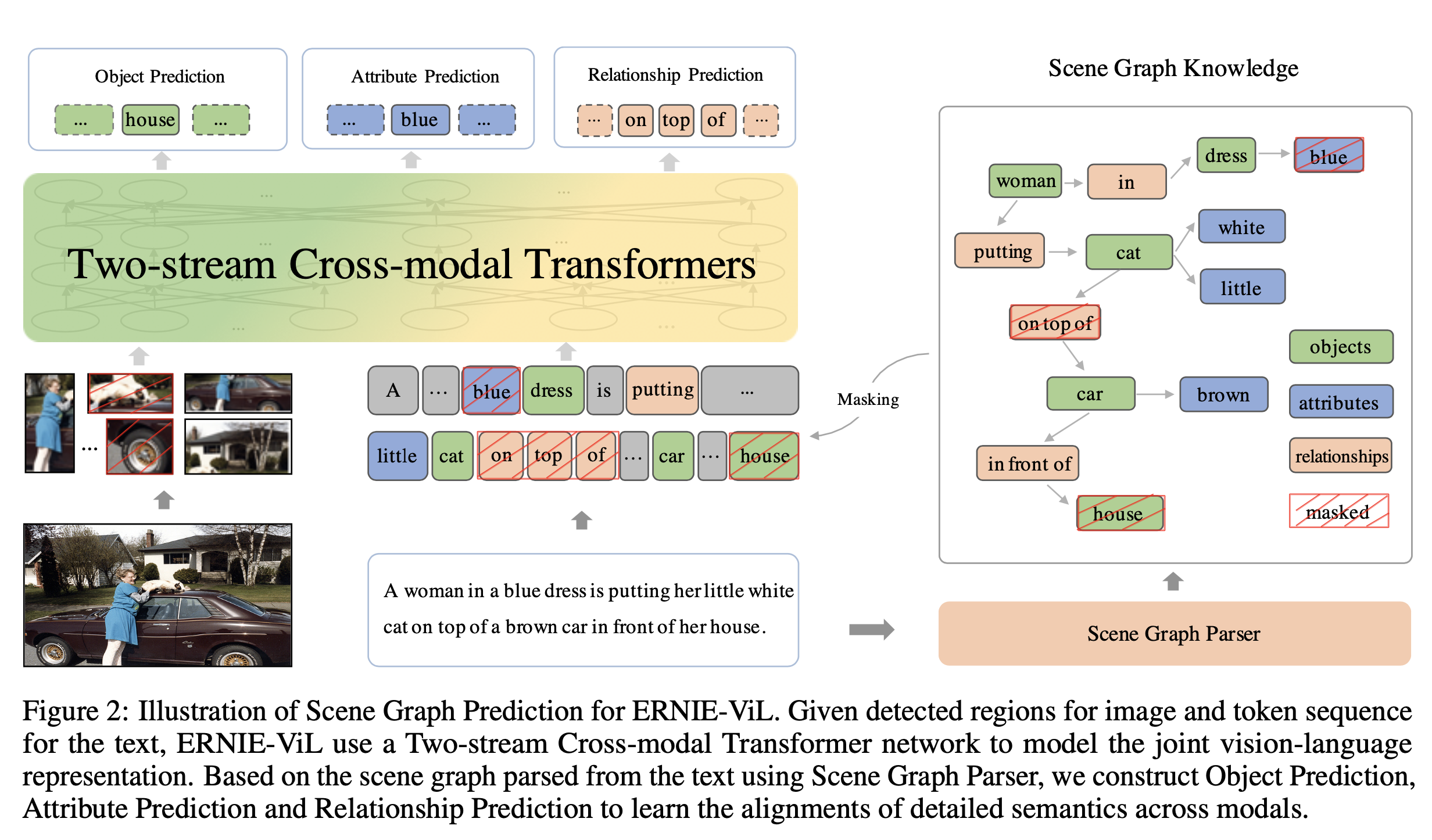
基于类似的想法, 为了提取出关键的内容部分, ERNIE-VIL 将场景图引入到多模态预训练任务中来。场景图主要有三部分组成 物品、属性、关系,如下图所示:

在图像描述中,如果可以很好的抓住这些细粒度的语言特征,那么就可以很好的将图片分开来,进而提升多模态预训练的效果。

当我们看到图片时,我们首先关注到图片中的物品(Objects) 、 特点属性 (Attributes) 和物品之间的关系。 以这张图片描述为例,人、车、房子、猫、树组成了图片的基本元素。而物品的属性,如白色的猫、穿蓝色衣服的女人、棕色的汽车则是对物品进行更详细的刻画。物品之间的位置和语义关系如 “猫在车上”、“车在房前”构成了物体间的关联。 我们通过物品、属性、关系可以描述出一个视觉场景的细粒度语义。
具体实现方法
对象预测
与 BERT 的 mask 任务类似,ERNIE-VIL 选取 30% 的对象进行 mask,其中 80% 会将原始对象替换为 [MASK] ,10% 会随机替换成其它 token ,还有 10% 会保持不变。随机选取图像中的一部分物体,如图中的”car”,将其在句子中对应的词进行掩码处理,模型根据文本上下文和图片对被掩码的部分进行预测。损失函数设计,最小化负对数似然:

属性预测
采用与 Object Prediction 相同的 mask 方案。对于场景图中的物体-属性对,如

关系预测
随机选取一部分“物体-关系-物体”三元组,如

预训练设计
提取文本中的 物品、属性、关系 是一个经典的任务,好消息是我们不需要那么精确。所以使用一个叫 SPICE 的工具,帮我们实现文本场景的提取。提取效果如下图所示

那将上边的步骤合并在一起,就可以得到这样的结构了。
实验
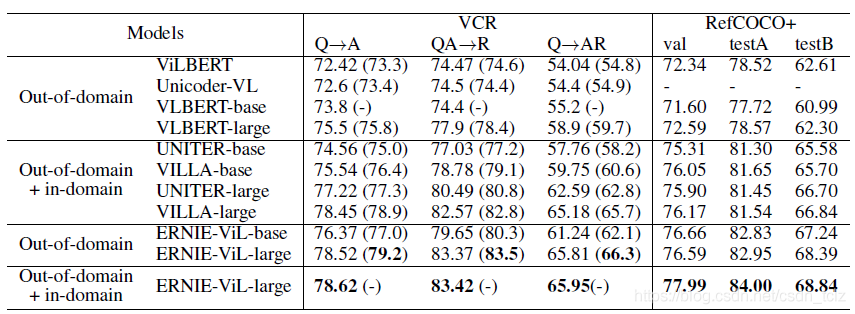
目测在多个任务上取得了 SOTA 的效果
结论
与 CLIP 的粗暴负样本构造不同,ERNIE-VIL 借鉴 NLP 的 MLM 设计, 并增加了 ERINE 的祖传艺能( knowledge mask )。

实现在较少训练资源和训练数据的前提下,依然达到了较好的效果。
ERNIE-ViL:Knowledge Enhanced Vision-Language Representations Through Scene Graph