ViLBERT:Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
背景
Paper: NeurIPS 2019
Code: https://github.com/facebookresearch/vilbert-multi-task
《ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks》来自 NeurIPS 2019 的一篇论文 ,本文将 NLP 领域内热门的 BERT 模型扩展为多模态的版本,即 Vision and Language, 因此作者将该模型起名为 ViLBERT。
实现方法
模型设计
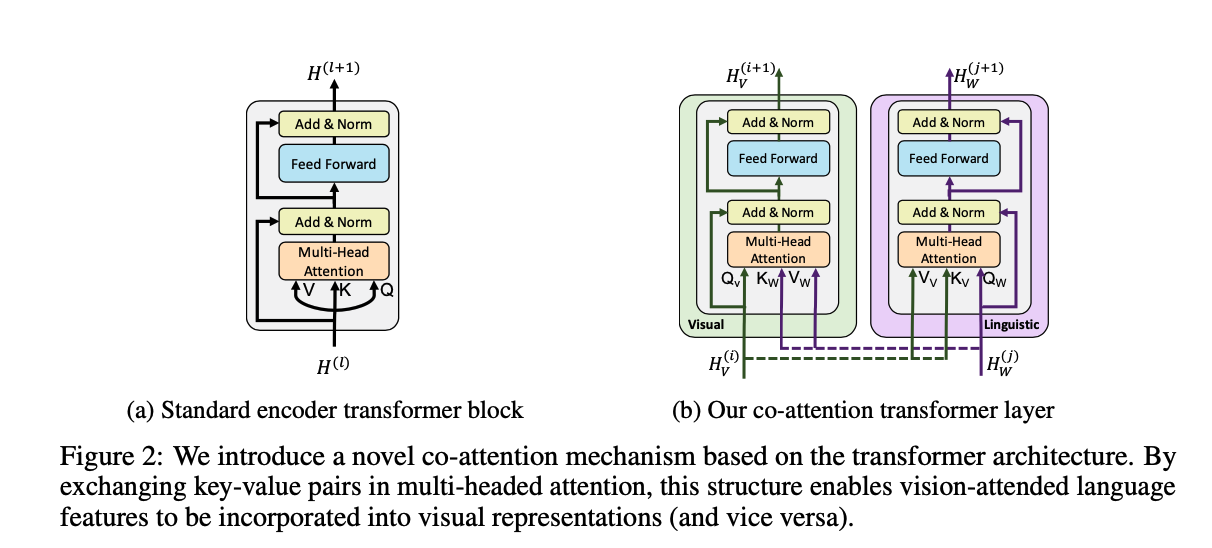
模型设计的想法非常简单,与 BERT 的模型结构相似,但是在 Multi-Head Attention 上动了手脚。
如图 2b 所示,作者引入了一个 co-attentional transformer layer(Co-TRM),给定中间视觉和语言的表示,该模块计算 query,key 和 value 作为其他模态 多头注意力模块的输入。因此,注意力模块在产生 attention-pooled features 的时候,是依赖于其他模态的。
剩下的 transformer(TRM) 模块像之前一样,包含一个残差。
算法实现
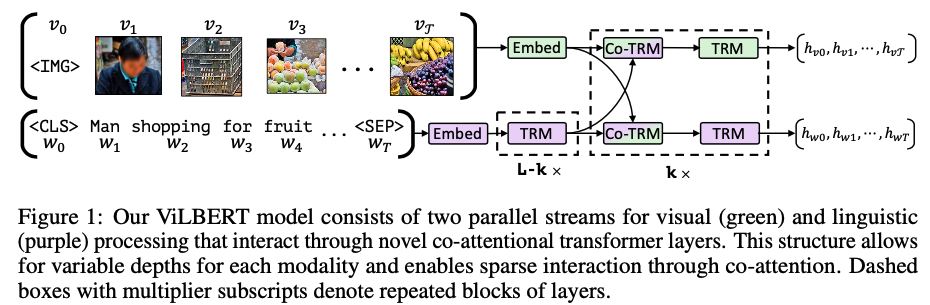
文本侧使用 BERT 提取 embedding, 图像侧使用大家都在用的 https://github.com/peteanderson80/bottom-up-attention 进行 object 提取,比如上图中的 人、购物车、水果等,这些部分都会组合为一个 5-d 的 embedding。
注意,这里用到了多层的 TRM ,只有在特殊层之间才会有交互操作(即 Co-TRM),如图1所示,Text 和 Imgae 侧会分别产出 embedding。
预训练任务
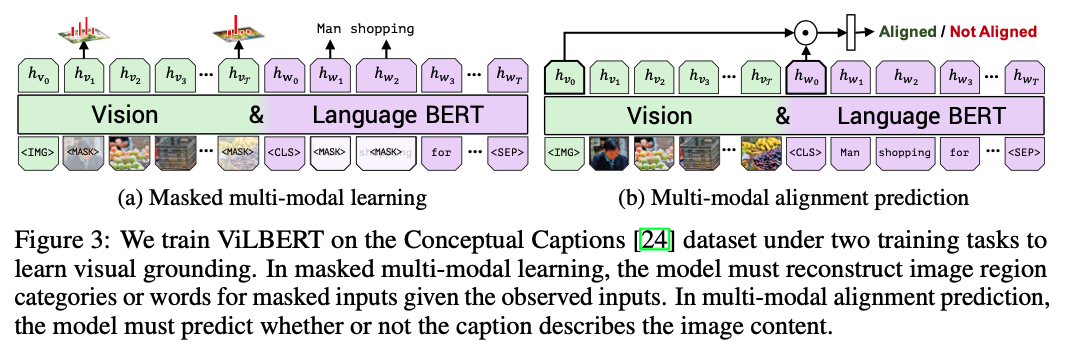
与 bert 的 mask 方法类似,作者设计了 The masked multi-modal modelling task ,以 15% 的概率 mask 掉文本或者图像区域,80% 替换为 [MASK] 标签,10% 随机替换掉, 10% 不做处理。
文本的 mask 在 bert 上很常见,根据 mask 位置的 embedding, 映射到所有词上,计算出交叉墒来就可以算 loss 了。 但图像的 mask 就比较少见了,上边提到每个图像区域的输入实际是一段 embedding,mask 掉这一段的 embedding 后,实际上也可以学习出一个 embedding 来。
但此时需要比较的就是原始embedding 和学习出的 embedding 间的 k-l 散度了,以此得到优化的 loss
遗留问题
1、已经很多次看到 https://github.com/peteanderson80/bottom-up-attention ,可能得抽空看一下论文和怎么代码。
2、k-l散度的相似分是怎么实现的。
总结
本文将 NLP 中非常火热的 BERT 模型拓展为了 多模态的版本,即:Vision + Language,称为 ViLBERT。该模型包含两个并行的流,分别用于编码 image 和 language,并且加入了 co-attention transform layer 来增强两者之间的交互,得到 pretrained model。作者在多个 vision-language 任务上得到了多个点的提升。
co-attention 对于 vision-and-language 来说并不是一个新的 idea,但是效果却很好。
ViLBERT:Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks