CLIP :Contrastive Language-Image Pre-Training
背景
论文来自 opai 2021 年提出的一个成果,相关可参考信息: github 、 paper 。 之前其实并不太了解多模态预训练领域的成果,最近看到了这篇质量很高的成果。
效果
我们可以运行这个 colab , 该作者将 Unsplash 的所有素材计算了 clip image embedding ,然后使用 clip word embedding 进行配图。
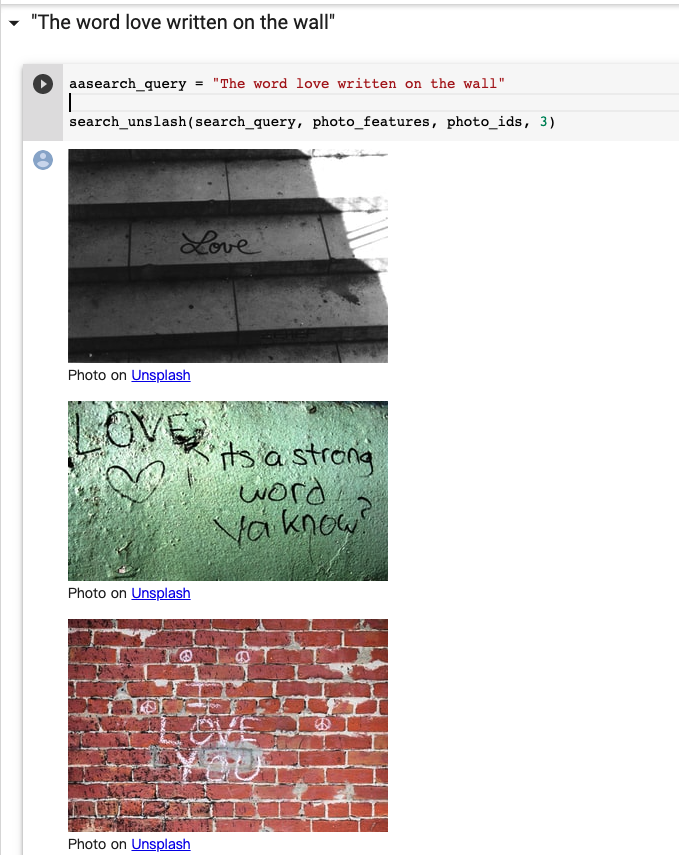
效果看起来似乎不错,几乎实现了通过一句话就找到合适的图片。 不可否定,会存在大量的 badcase。但是在不需要 fine-tune / 下游任务,直接 zero-shot 得到的 embedding 可以实现这样的效果已经很厉害了。
OpenAi 做法
数据处理
论文非常模糊的提到了自行收集了 4 亿的文本图像对,


在 queries 右上方有个 1 , 提到 「The base query list is all words occurring at least 100 times in the English version of Wikipedia」。
这里提到使用了 50w 的query,并且每个 query 配了最多 2w 张图。超多的配图可以限制的减少噪声,并确保数据在 其他数据集上有较好的泛化能力。
如果 openai 真的想办法给 query 找到了 2w 张图,还是蛮恐怖的。
文章后边其实也提到了,除了普通的互联网数据集。 他们还做了一些 PROMPT ENGINEERING 这个东西怎么理解呢?我们举例来说
因为测试的数据集,如 ImageNet 等,其实图片只有一个标签,比如 猫狗猪 等。 但是 CLIP 的训练数据都是句子诶,那这个怎么对齐?作者设计了一个模版 比如 “A photo of a {label}.” 这个样子,将标签转化成一句话来处理,这样转化后效果有 1.3% 的提升。
类似的,对于 ocr 数据集,作者使用 “a satellite photo of a {label}.” 这样的描述
此外,作者还设计了一种更复杂的 assembly 的方法,使用80种模板, 参考 github 第 9 个 input。 将每个词放进去,组合出 80 个句子,分别计算出 embedding 后做一个平均。效果又有了 3.5% 的提升。

也就是这个样子
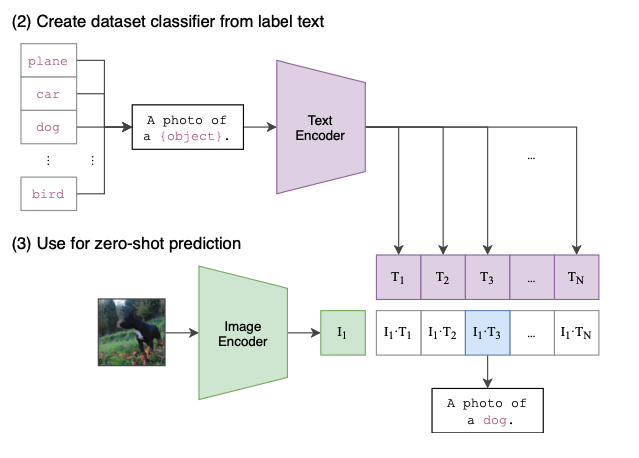
看到这里的时候,我其实有一点怀疑,高质量的标注数据集其实还蛮多的,比如 flickr30k、 ms-coco、 imageNet 等。 那这 4 亿训练数据中,会不会包含了一些高质量的标注数据集。
模型设计
模型设计其实没有太多可以讲的地方,代码已经开源了,具体可以看 https://github.com/openai/CLIP/blob/main/clip/model.py , 这里我记一些自己觉得有意思的设计。
_transform 阶段中
- 图片 resize 后经过了一个 CenterCrop ,没有旋转等复杂操作。
- norm 参数是 clip 自己训的,不是 pytorch 标准的 norm 参数。
视频的模型共有四种,具体为这四种, 但似乎主要都在用 ViT-B/32。

CLIP 使用了一种图片和文本分别进行编码,最后计算相似度的经典双流结构。
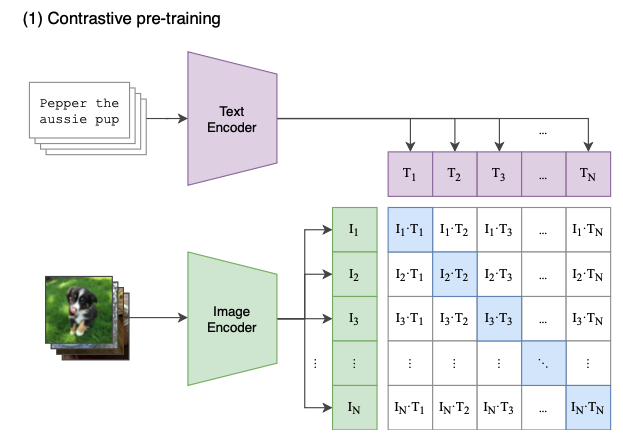
图片侧使用 Resnet 50 或者 Vit,文本编码器使用了 Tranformer 结构,未用到预训练的知识,看起来是从头开始训练的。 (毕竟数据量大

openai 使用到了一个非常大的 batch size 32768 , 32768 是 2 的 15 次方。
对一个 batch 内的数据,我们进行交叉组合,这里的 N 应该就是 2 ^ 15 ,那整个训练矩阵的大小就是 2 ^ 15 * 2 ^ 15 ,也就是 2 的 30 次方大小的一个矩阵, 其实还蛮恐怖的这个size。
再看一眼这个任务,现在有 N^2 图片文本对,其中 N 个是正样本,作者希望正样本的 image-text 的 embedding 距离越近越好。其余的 N^2 - N 个是负样本,希望可以最小化其 embedding 相似度。
- 在 image 和 Text 侧分别拿到 embedding 后,使用一个线性映射,将两者映射到同一个数学空间内。

大量的计算资源
这里提到了两个模型,如 DN50x64 和 vit-L/14 ,线上的 vit 应该就是后者,目前来看效果是最好的。

分别耗费 592 个 V100 + 18天 的时间 和 256 个 V100 + 12天 的时间。 更别提大量的数据收集整理,多个 gpu 之间的任务分配,整个项目看下来很是很厉害的。
小结
1、我看到很多人对 zero-shot 感到疑惑,reddit ,一般在 nlp 中,zero-shit 可能更像是生成模型的感觉。 但作者论文中解释道,没有见过的数据集也算 zero-shot ,这个的确容易让人觉得困惑。

2、俗话说 「一力降十会」,很多的论文设计非常巧妙的结构用于优化算法结果。 但 openai 这个项目就很结暴力美学了,我想到小时候看电影时的台词,在绝对的力量面前,技巧就不那么重要了。
3、常见的图像分类任务得到的模型,对新类别的支持能力可能比较堪忧。 CLIP 提高了模型的泛化能力,在我们自己的使用中,发现模型对句子,人名也有不错的效果。
参考
Adversarial examples for the OpenAI CLIP in its zero-shot classification regime and their semantic generalization https://stanislavfort.github.io/2021/01/12/OpenAI_CLIP_adversarial_examples.html
如何评价OpenAI最新的工作CLIP:连接文本和图像,zero shot效果堪比ResNet50? - 知乎 https://www.zhihu.com/question/438649654
CLIP :Contrastive Language-Image Pre-Training