K-L 散度
Kullback-Leibler Divergence,即K-L散度,是一种 量化两种概率分布P和Q之间差异 的方式,又叫相对熵。
在概率学和统计学上,我们经常会使用一种更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息量。
数据的墒
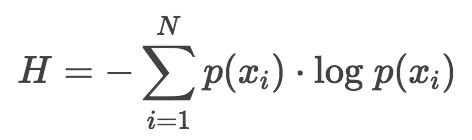
如果我们使用以 2 为底数的对数来计算 H 值的话,可以将这个值表示为编码该信息最少需要的二进制位数个数 bits 。
K-L 散度度量信息损失
设 p 为观察得到的概率分布,q 为另一分布来近似 p , 则 p、q 的 K-L 散度 为:

如果用 2 为底进行对数计算,则 K-L散度值表示信息损失的二进制位数,下面公式以期望表示 K-L 散度。
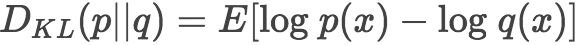
更常见的写法为:
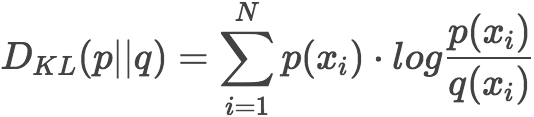
散度并非距离
很自然地,一些同学把K-L散度看作是不同分布之间距离的度量。这是不对的,因为从K-L散度的计算公式就可以看出它不符合对称性(距离度量应该满足对称性)。
也就是说,用p近似q和用q近似p,二者所损失的信息并不是一样的。
其他
信息熵、交叉熵、相对熵
- 信息熵,即熵,香浓熵。编码方案完美时,最短平均编码长度。
- 交叉熵,cross-entropy。编码方案不一定完美时(由于对概率分布的估计不一定正确),平均编码长度。是神经网络常用的损失函数。
- 相对熵,即K-L散度,relative entropy。编码方案不一定完美时,平均编码长度相对于最小值的增加值。 更详细对比,见知乎如何通俗的解释交叉熵与相对熵?
为什么在神经网络中使用交叉熵损失函数,而不是K-L散度?
K-L散度=交叉熵-熵,即
DKL(p||q)=H(p,q)−H(p)。
在神经网络所涉及到的范围内,H(p)不变,则DKL(p||q)等价H(p,q)。
参考:
如何通俗的解释交叉熵与相对熵? - Agenter的回答 - 知乎 https://www.zhihu.com/question/41252833/answer/141598211
https://www.jianshu.com/p/43318a3dc715
https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained