Supervised Contrastive Learning
背景
Paper: NeurIPS 2020
Code: https://github.com/HobbitLong/SupContrast
《Supervised Contrastive Learning》是来自于 NeurlPS 2020 的论文,本文主要介绍了一种提高 feature 质量的对比学习方法,有别于之前的 自监督对比学习,是一种 有监督对比学习
对比学习(分类算法)
具体做法
为了帮助理解,我们先讲一下传统做法,以 ImageNet 类图文多模态数据集为例。我们通过将文本和图片 batch 的进行训练,形成这样的数据格式。
先将数据处理成 <图片,文本> 对的形式
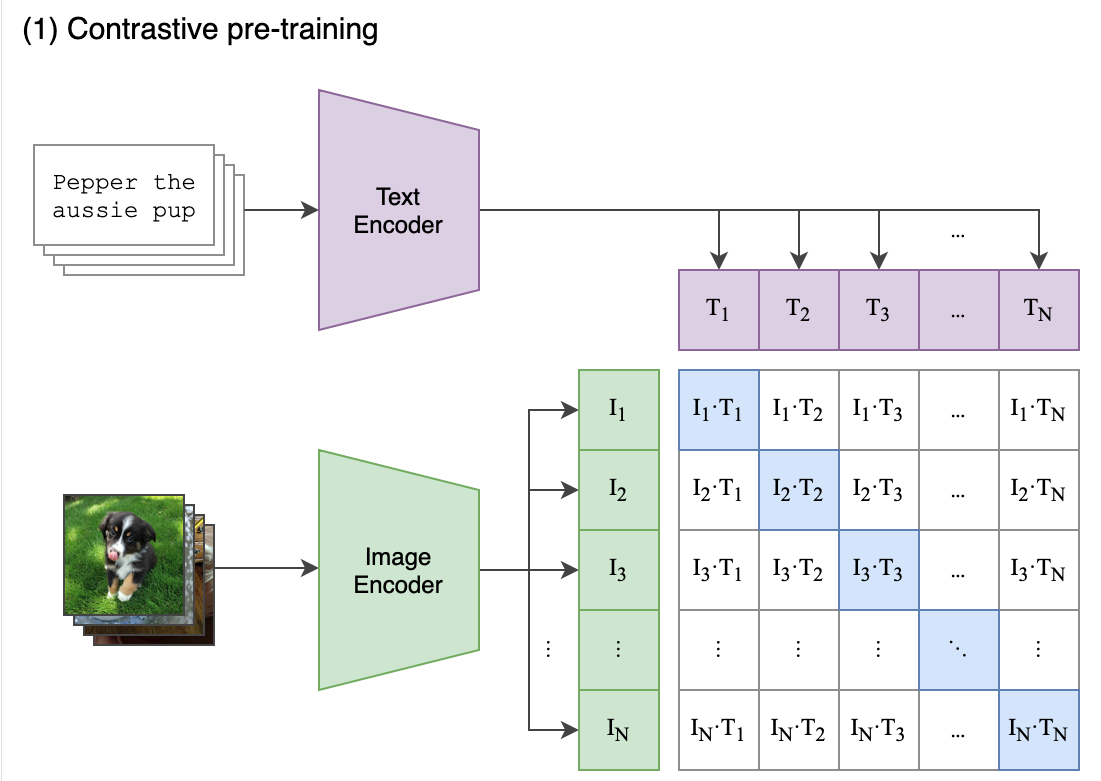
假设每个 batch 有 N 个文本图像对, 则共可能会有 N^2 个组合,但只有对角线上的N个是正样本。
那么我们的模型就可以用 cross entropy 来学习,当前 image_a embedding 和其余的 text embedding 计算 cosine 得到最相近的 text_x ,预测值 text_x 与实际值 text_a 可以理解为两个 id ,这时就可以用交叉墒计算 loss,优化模型了。
优点
每个图片有自身对应的描述,但没有负样本, 如何构造负样本一直困扰着我们。
通过这种 batch + cross entropy 的方式,统计上讲同一 batch 的其他元素基本可以认为是负样本,于是一个没有标注的数据集,就被转化为一个分类数据集了。
自监督对比学习
交叉墒在上段描述的情况中,表现的非常成功,大多数情况下,我们直接使用交叉墒就可以获得 sota 的结果。
google 在这篇论文中提到了两种优化方法,在开始介绍 Supervised Contrastive Learning 前,先介绍了一下 Self Supervised Contrastive Learning。
那如何做到 自监督对比学习 呢?
自监督学习的核心是如何给数据产生一个新的标签,然后用这个标签进行某种 “监督学习”。 在 cv 场景下,常见的做法如: 将原始的图片进行一个随机的旋转,然后用处理后的图片作为输入,训练网络预测图片到底旋转了多少角度。
本文提到的自监督对比学习,使用了如下的方法:
1、假定现在有 N 个图片,使用 AutoAugment, RandAugment, SimAugment, Stacked RandAugment 。 这些数据增强的方法我还没看完,我理解应该是对原始的图片做一些如 裁剪, 变形, 旋转等操作。 使得原始的每张图片产出多张新的图片 (论文内做了好多次实现,为了方便前期理解,我们假设每张旧图片产出两种新图片,此时有 2N 张图片), 作为后续的输入进入模型。
2、经过 Network 计算后, 2N 个图片得到 2N 个 feature, 对每个 feature 进行 normalization , 使其成为单位向量,假设得到的 feature 是 $z1,z_2,….z{2N}$, 这样每个 feature 可以落在一个超球面上。
3、对于第 i 张图,在剩余的 2N-1 图片中,存在对应的图片j。 i 和 j 来自于同一张图片,所以让图片 $z_i, z_j$ 的距离越近越好。 而除了 i 和 j 外,其余 2N-2 张图片,与 $z_i$ 的距离越远越好。
我们回忆一下交叉墒的定义:

和 softmax

我们再来看本文涉及的 Self-Supervised Contrastive Loss ,先前说过了 $z_i,z_j$ 都是单位向量,那么两者的内积就是相关分数。

log 右侧的部分,构造了一个类似 softmax 效果。并实现了两个效果:
1、图片 i 和 j 的 feature 的内积 (余弦)越大越好,越大 loss 越小;
2、图片 i 和 其他来源不同的图片的 feature 的 cos 距离总和越小越好,越小 loss越小。
我感觉这里和 softmax 与 ce 的设计非常像,但又有了一些新的信息在。
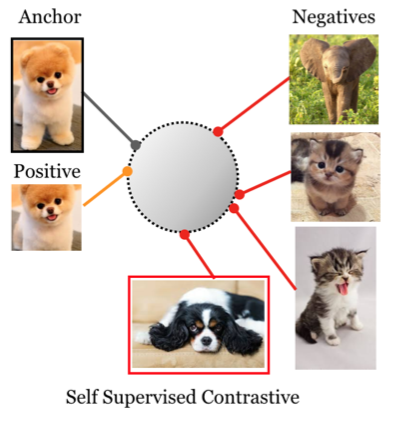
以上图为例,可以看到 Anchor 也就是这里的 i 是一只黄头狗,黄头狗的图片被裁减后得到了看不到腿的黄头狗 j。 我们希望将 i 和 j 的距离越近越好,其他越远越好。
这里其实引出了一个新的问题,我们发现有的 黑头狗 似乎被推的有点远的,反而和其他的黑头猫离得很近,这其实是不太应该的。 直觉上讲,狗和狗的距离应该比较近才对。 于是引出了 Supervised Contrastive Learning 。
监督对比学习
为了让同类图片的feature彼此接近,需要使用类别信息来判断哪些图片属于同一个类,因此,方法的名字从“自监督”变成了“监督”。对比学习的依据,从“是否来源于同一张图片“,变成了”是否属于同一个类“。训练使用的loss函数变为:

这里的 $P(i)$ 是所有的与 $i$ 同一类别的正样本,$I$ 是所有的样本。
以 $\mathcal{L}^{sup}_{out}$ 来看, $\frac{1}{p(i)}$ 对所有正样本计算结果做平均,log 内的部分与自监督对比学习的很像,也是为了实现 将同类的其他图片 feature 拉近,推远非同类图片的 feature 。
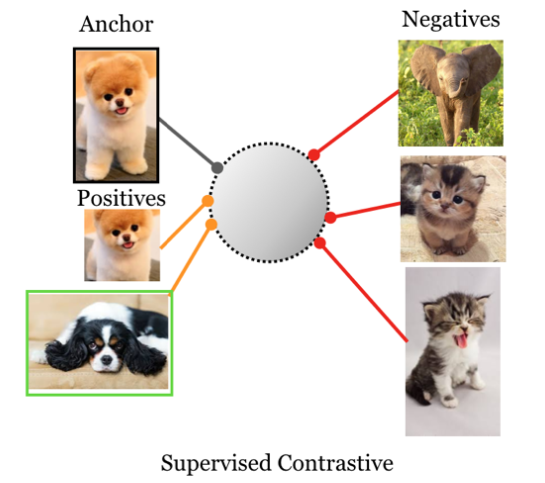
以上图为例,该设计尝试将同类图片的feature放在一起,推远不同类的图片。
总结
Supervised Contrastive Learning 论文实验非常充分,公式的推导也很扎实。 具体可以看这里 https://proceedings.neurips.cc/paper/2020/hash/d89a66c7c80a29b1bdbab0f2a1a94af8-Abstract.html ,是一篇很优秀严谨的论文。给人耳目一新的感觉,但论文中提到的诸多数据增强的方法,我的了解都很有限,后续会再看一些相关的论文。
交叉熵(Cross-Entropy) https://blog.csdn.net/rtygbwwwerr/article/details/50778098
Softmax函数与交叉熵 - 杀手XIII的文章 - 知乎 https://zhuanlan.zhihu.com/p/27223959
Self-Supervised Representation Learning https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
uy
Supervised Contrastive Learning