Python爬取图片(使用urllib2)
上篇文章 使用 XPath 提取网页信息 之后,将链接中的内容下载至本地,需要使用到 urllib2 。
urllib2 简介
urllib2提供一个基础函数urlopen,通过向指定的URL发出请求来获取数据。最简单的形式就是:
1 | import urllib2 |
可以将上述代码看作两个步骤,我们指定一个域名并发送请求1
request=urllib2.request('/')
接着服务端响应来自客户端的请求
1 | response=urllib2.urlopen(request) |
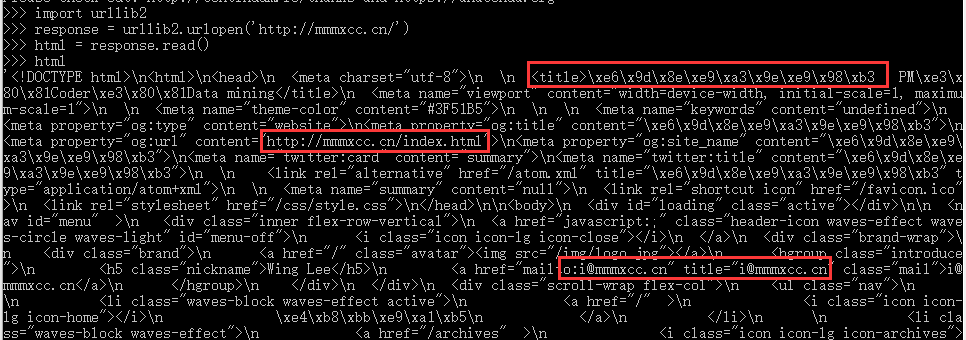
我们可以发现title这个地方本来应该是中文的,但因为编码的原因,导致出现乱码。通过将html页面重新用”utf-8”编码,可以解决这个问题。
将获得的response保存至本地
使用Xpath表达式提取图片链接
详见上一文章 /2016/12/13/get_html/ ,关于XPath和beautifulsoup,可以参考python中的beautifulsoup和xpath有什么异同点?
这里需要导入lxml,代码格式如下。
1 | import requests |
单独运行 以上代码可以获得
设置保存的位置
需要使用到os库中的 os.chdir(r””)函数,””中间插入地址。注意这个位置必须是存在的,如果位置不存在,函数会报错。因为该函数的意义是:将工作空间从python代码所在位置,改为指定的这个位置。
模拟正常浏览器下载图片(如果Python下载的图片不显示 )
有时你会碰到,程序也对,但是服务器拒绝你的访问。这是为什么呢?
问题出在请求中的头信息(header)。 有的服务端有洁癖,不喜欢程序来触摸它。
这个时候你需要将你的程序伪装成浏览器来发出请求。请求的方式就包含在header中。
1 | header = { |
可以看到urllib2.Request()里边加入了一个header,用于模拟浏览器访问,第二个位置None表示data,用Python官方文档的说法:Sometimes you want to send data to a URL (often the URL will refer to a CGI (Common Gateway Interface) script [1] or other web application). With HTTP, this is often done using what’s known as a POST request.
暂时我们用不着,所以不深究,等我碰到这个问题了再说。
为图片命名(下载图片只有一张)
在获得response之后,将图片直接保存为某个特定名字的话。会导致之后抓取到的图片顶替掉之前的图片,导致图片看起来只有一张。
1 | with open("%s.jpg" %name, "wb") as f: |
使用with as语句,将文件名保存为%s.jpg,类似于C语言的输出。循环结束的时候name++,保证文件名不重复。
使用with as 函数
Python’s with statement provides a very convenient way of dealing with the situation where you have to do a setup and teardown to make something happen. A very good example for this is the situation where you want to gain a handler to a file, read data from the file and the close the file handler.
有一些任务,可能事先需要设置,事后做清理工作。对于这种场景,Python的with语句提供了一种非常方便的处理方式。一个很好的例子是文件处理,你需要获取一个文件句柄,从文件中读取数据,然后关闭文件句柄。
Without the with statement, one would write something along the lines of: 如果不用with语句,代码如下:1
2
3file = open("/tmp/foo.txt")
data = file.read()
file.close()
使用with as之后代码为:1
2with open("%s.jpg" %name, "wb") as f:
f.write(response.read())
总结
本文通过XPath表达式提取页面图片链接,使用urllib2下载,其中使用header模仿浏览器访问。解决了以下问题:
- Python下载的图片不显示
- 下载图片只有一张
- 设置保存的位置
- 使用with f函数
效果如下: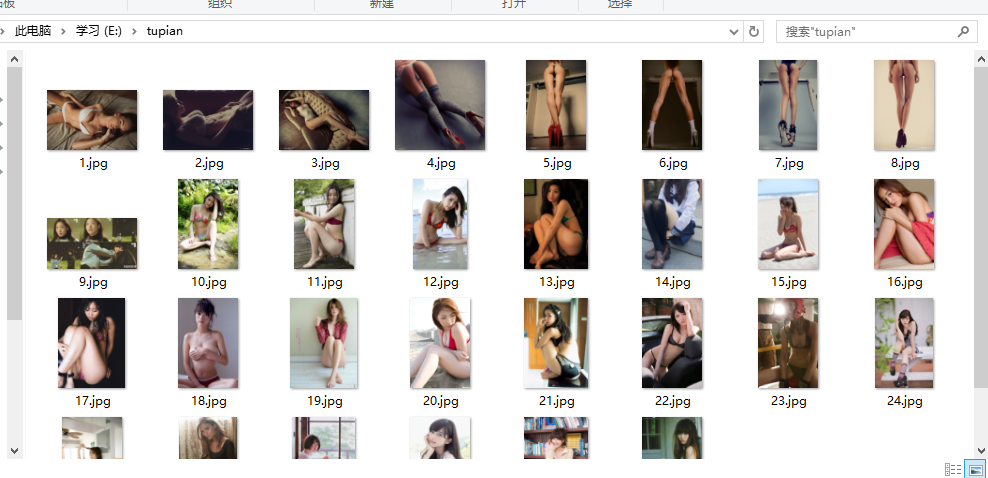
完整代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# coding=utf-8
import requests
import urllib2
import os
from lxml import etree
html = requests.get("http://cl.d5j.biz/htm_mob/7/1612/2172569.html")
html.encoding = 'utf-8'
selector = etree.HTML(html.text)
content = selector.xpath('//table//img/@src')
for imgurl in content:
name = imgurl[-9:];
os.chdir(r"D:")
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.114 Safari/537.36',
'Cookie': 'AspxAutoDetectCookieSupport=1',
}
request = urllib2.Request(imgurl, None, header) #刻意增加头部header,否则本行与下一行可以写为:response = urllib2.urlopen(imgurl)
response = urllib2.urlopen(request)
f = open(name , 'wb')
f.write(response.read())
f.close()
print(imgurl)
代码重新修改了一下,上手运行会发现D盘有惊喜哦~
加入print(imgurl),运行起来更洋气~
Python爬取图片(使用urllib2)