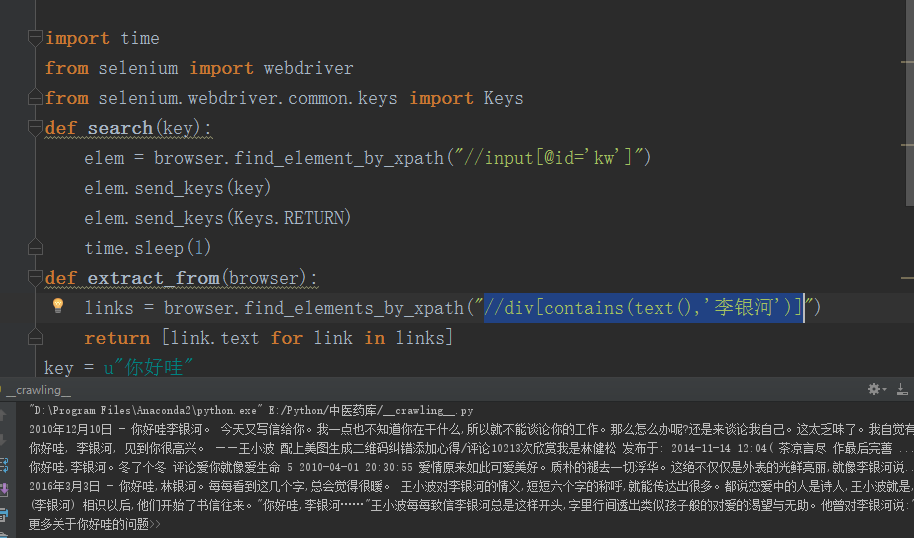
defextract_from(browser): links = browser.find_elements_by_xpath("//p[contains(text(), '出处') or contains(text(), '组成') or contains(text(), '组成') or contains(text(), '主治') or contains(text(), '用法')] ") print(browser.title) return [link.text for link in links]
defextract_from(browser): links = browser.find_elements_by_xpath("//p[contains(text(), '出处') or contains(text(), '组成') or contains(text(), '组成') or contains(text(), '主治') or contains(text(), '用法')] ") print(browser.title) return [link.text for link in links]
from lxml import etree html = requests.get("http://www.zk120.com/fang/") html.encoding = 'utf-8' selector = etree.HTML(html.text) content = selector.xpath("//ul/li/a/span[@class='free_icon_r']/../@href") for imgurl in content: imgurl = "http://www.zk120.com" +imgurl browser = webdriver.Chrome() browser.get(imgurl) time.sleep(2) print ('\n'.join(extract_from(browser))) print("------------") browser.close()
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC
defextract_data(browser): links = browser.find_elements_by_xpath('//i[@class="RecordStats"]/a') return [link.get_attribute('href') for link in links]
# get max pages element = WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH, "//p[@class='c'][last()]"))) max_pages = int(re.search(r'\d+ de (\d+)', element.text).group(1), re.UNICODE)
# extract from the current (1) page print"Page 1" print extract_data(browser)
# loop over the rest of the pages for page in xrange(2, max_pages + 1): print"Page %d" % page