使用 XPath 提取网页信息
以1024举例,使用XPath提取图片链接以及磁力链接地址。
学习XPath的基本知识
推荐 Xpath教程 很容易理解。
推荐可以将常用的语法记下来,不常用的可以等用的时候再查。
推荐使用Chrome浏览器中的XPath Helper,良心之作.
左边输入XPath表达式,右侧会自动展示结果。
选择元素之后按下ctral + shift + x,可以自动提取该元素的XPath表达式。
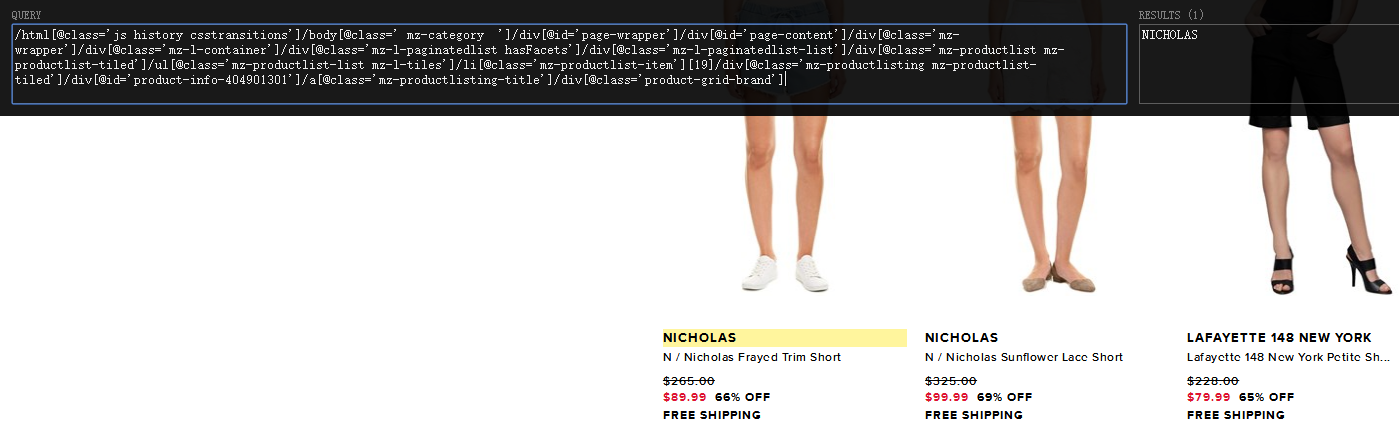
常用语法
- / 从根节点选取。
- // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
- @ 选取属性,常见使用方法为[@class = “title”]
举例,比如在双面胶-淘宝搜索 页面
输入: //*[@class=”m-itemlist”]//a[@trace-price<20]/@href,用来提取出class为itemlist内a标签里所有price 小于20的产品,并将其href(即超链接)输出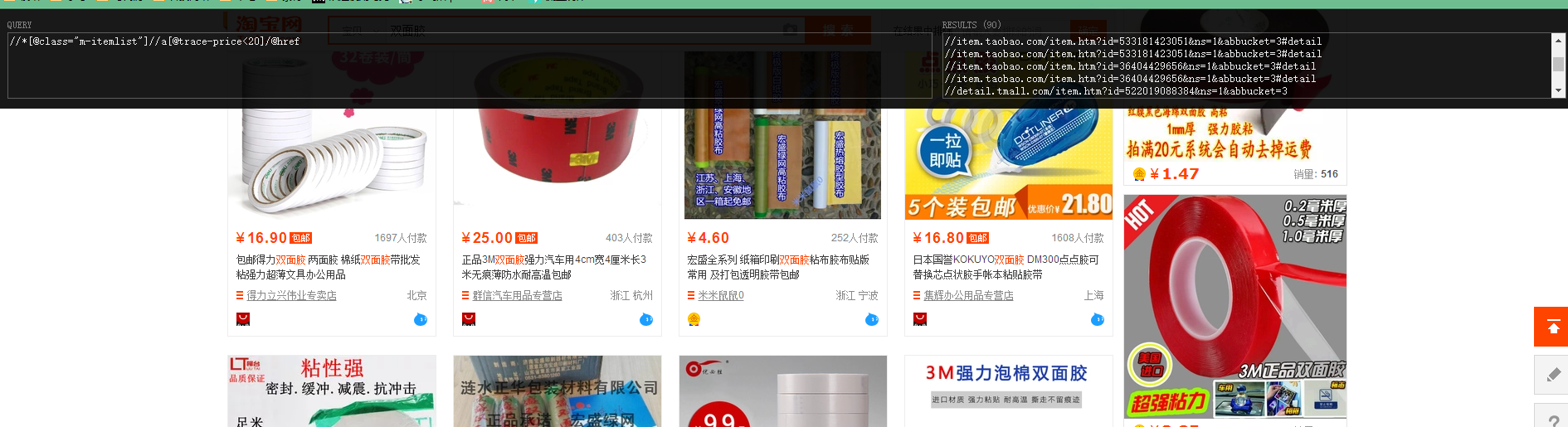
需要结合Chrome浏览器的F12一起使用,先选定大致的框架,比如itemlist这个class,然后逐渐加上更多的要求,具体见文首给出的链接学习。
知道这些就可以抓取1024上的图片和磁力链接了,目测是不是很简单
挑选网页实验一下
作为一名1024资深游客,首先在技术讨论区选择一篇好文,这里用的是[榴民资讯]11月精品主题推荐(49期)
使用F12查看网页的结构
有两个主要标签 header 和 main ,鼠标移动到main上,可以看到内容页面都被包含起来,所以第一个节点应该选main。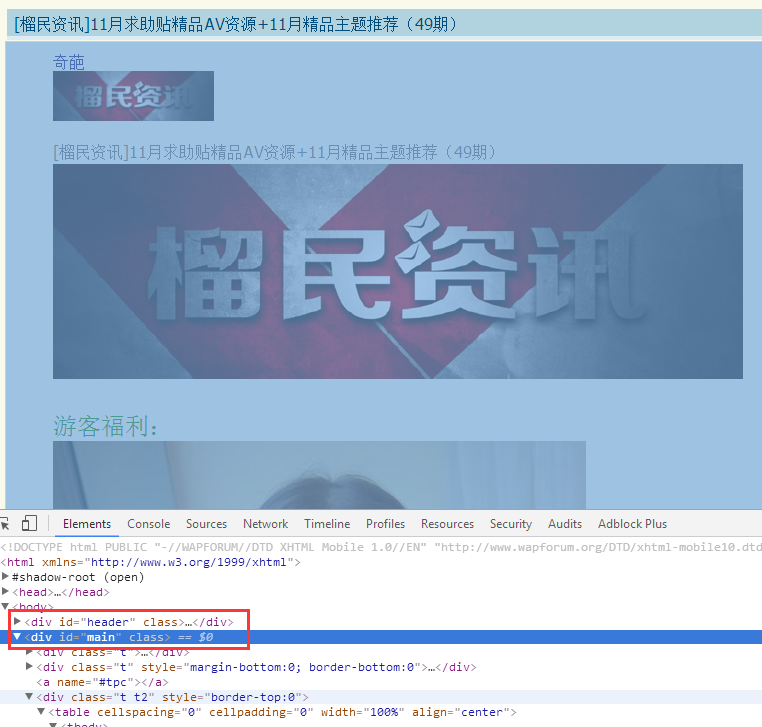
使用XPath表达式筛选图片链接
我们看到图片前边都有一个属性src,这个src后边就是我们所需的图片链接。
综上,使用XPath表达式: //*[@id=”main”]//@src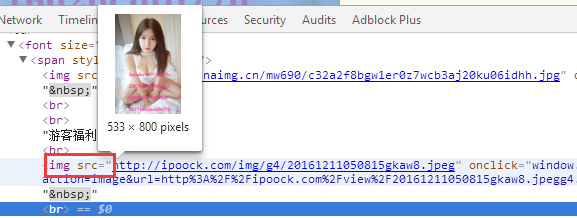
输入XPath代码,获得图片链接。
使用XPath表达式筛选磁力链接
同理,我们可以发现,磁力链接前边都有一个blockquote,与上一条处理方式类似,使用XPath表达式: //*[@id=”main”]//blockquote

以上
使用 XPath 提取网页信息