CS224n自然语言处理与深度学习 Lecture Notes One
本笔记主要内容翻译自斯坦福大学CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I,内容大部分抄袭自: huangzhanpeng.github.io
Word Vectors
大约一共有 $13m$ 个英语单词,它们都是没有关系的吗?
例如 $feline$ 和 $cat$,$hotel$ 和 $motel$ 是有关系的。因此,我们希望用词向量编码单词使它代表在词组空间中的一个点。
重要的原因有很多,但最直观的原因是,实际上可能存在一些 $N$ 维空间(例如 $N \ll 13m$),这足以编码我们语言的所有语义。
每个维度都会编码一些使用语音传输的意思。例如,语义维度可能表明时态(过去、现在和未来),计数(单数和复数)和性别(男性和女性)。
我们从最简单的 $one\text{-}hot$ 向量的词向量方法开始:代表每个词都是一个 $\mathbb{R}^{|V|\times 1}$ 向量,其中除了该单词所在的索引为 $1$ 外其他索引都是 $0$。在这个定义下,$|V|$ 是词汇表的大小。这种词向量的可以如下表示
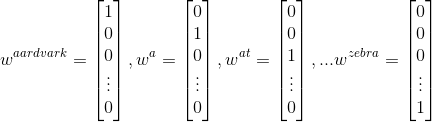
我们将每个单词表示为完全独立的实体,这样的单词表示没有给出任何直接相似的概念,例如,
SVD Based Methods
这是一类找到词嵌入的方法(即词向量),我们首先遍历一个很大的数据集和统计词的共现计数矩阵 $X$,然后对矩阵 $X$ 进行 $SVD$ 分解得到 $USV^{T}$。然后我们使用 $U$ 的行来作为字典中所有词的词向量。我们来讨论一下 $X$ 的几种选择。
Word-Document Matrix
我们最初的尝试,我们猜想相关连的单词在同一个文档中会经常出现。例如,“$banks$”,“$bonds$”,“$stocks$”,“$moneys$”等等,出现在一起的概率会比较高。但是“$banks$”,“$octopus$”,“$banana$”,“$hockey$”不大可能会连续地出现。我们根据这个情况来建立一个词-文档矩阵,$X$ 是按照以下方式构建:遍历数亿的文档和当词 $i$ 出现在文档 $j$,我们对 $X_{ij}$ 加一。这显然是一个很大的矩阵($\mathbb{R}^{|V|\times M}$),它的规模是和文档($M$)成正比关系。因此我们可以尝试更好的方法。
Window based Co-occurrence Matrix
这里使用相同的逻辑,但是矩阵 $X$ 变为一个相关性矩阵而不是单词共现统计数的矩阵。在这个方法中,我们统计每个单词出现在一个在该词附近的指定窗口中次数。我们在这个语料库中统计所有单词的计数。我们在下面展示了一个例子。让我们的语料库是仅仅由三句话组成和窗口的大小是 $1$:
- $I$ $enjoy$ $flying$。
- $I$ $like$ $NLP$。
- $I$ $like$ $deep$ $learning$。
计数矩阵的结果如下所示: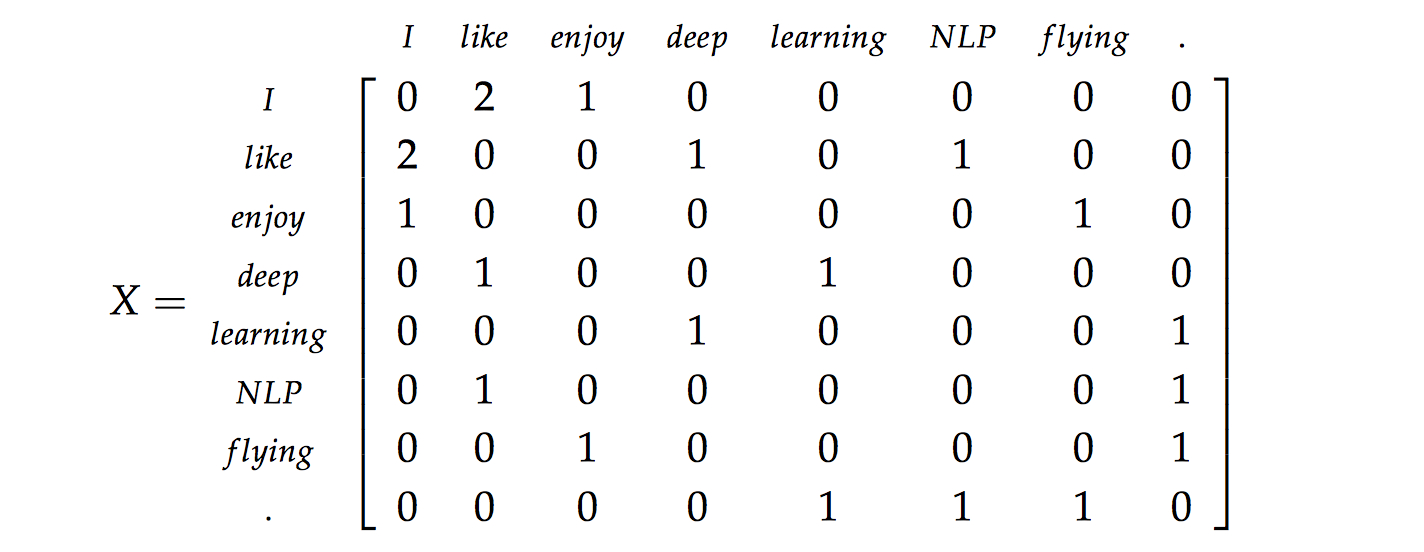
Applying SVD to the cooccurrence matrix
然后我们对矩阵 $X$ 使用 $SVD$,观察奇异值(矩阵 $S$ 上对角线上元素),根据期望的捕获方差百分比截断,留下前 $k$ 个元素:
然后我们取子矩阵 $U_{1:|V|, 1:k}$ 作为词嵌入矩阵。这就给出了词汇表中每个词的 $k$ 维表示。
对矩阵 $X$ 使用 $SVD$
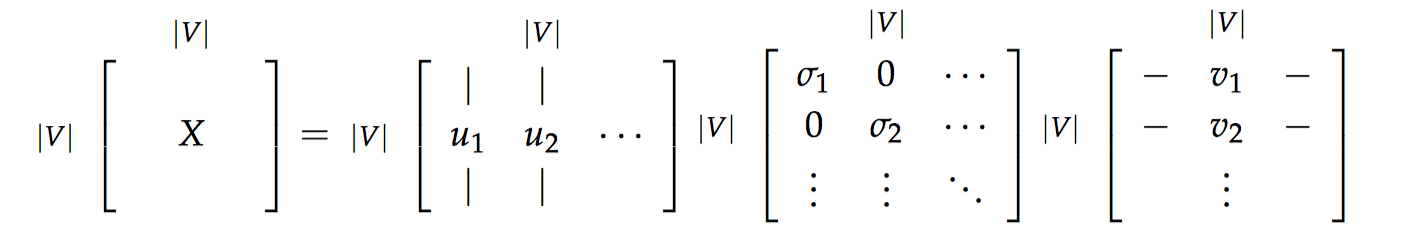
通过选择前 $k$ 个奇异向量来降低维度:
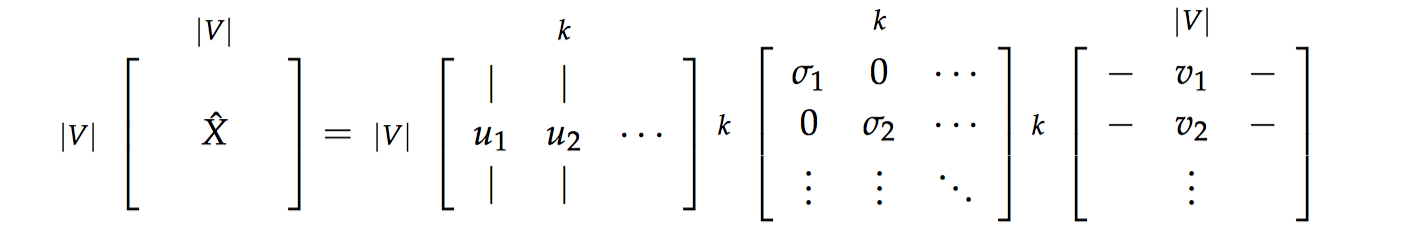
这些方法都能得到充分的语义和句法(词性标注)的信息,但是这些方法会出现许多问题:
- 矩阵的维度会经常发生改变(经常增加新的单词和语料库的大小会改变)。
- 矩阵会非常的稀疏,因为很多词不会共现。
- 矩阵的维度一般会非常高($\approx 10^{6}\times 10^{6}$)。
- 基于 $SVD$ 的方法的计算复杂度一般为 $O(n^{2})$。
- 需要在 $X$ 上加入一些技巧处理来解决词频的极剧的不平衡。
对上述讨论中存在的问题存在以下的解决方法:
- 忽略功能词,例如 the,he,has 等等。
- 使用 ramp window - 即基于在文档中词与词之间的距离给共现计数加上一个权值。
- 使用皮尔逊相关系数将负数的计数设为 0,而不是使用原始的计数。
在下一部分,基于迭代的方法可以以优雅的方式解决大部分上述的问题。
Iteration Based Methods - Word2vec
这里我们尝试一个新的方法。我们可以尝试创建一个能够一次学习一个迭代,并最终能够对给定上下文的单词的概率进行编码的模型,而不是计算和保留一个巨大的数据集的全局信息(可能含有数亿个句子)。
这个想法是设计一个模型,该模型的参数就是词向量。在每次模型的迭代,计算误差,并遵循一些更新规则,该规则具有惩罚造成错误的模型参数的作用,从而可以学习到词向量。
这个方法成为误差“反向传播”,这个方法使得训练模型的速度更快。
在这里,我们介绍一个非常有效的概率模型:$word2vec$。$Word2vec$ 是一个软件包实际上包含:
- 两个算法: $continuous$ $bag\text{-}of\text{-}words$($CBOW$)和 $skip\text{-}gram$。$CBOW$ 是根据中心词周围的上下文单词来预测该词的词向量。$skip\text{-}gram$ 相反,是根据中心词预测周围上下文的词的概率分布。
- 两个训练方法: $negative$ $sampling$ 和 $hierarchical$ $softmax$。$Negative$ $sampling$ 通过抽取负例来定义目标,$hierarchical$ $softmax$ 使用一个有效的树结构来计算所有词的概率来定义目标。
Language Models (Unigrams, Bigrams, etc.)
首先,我们需要创建一个模型来指派一个概率在一系列的单词上。我们从一个例子开始:
一个好的语言模型会给这个句子很高的概率,因为在句法和语义上这是一个完全有效的句子。相似地,句子“$stock\;boil\;fish\;is\;toy$”会得到一个很低的概率,因为这是一个无意义的句子。在数学上,我们可以称为对给定 $n$ 个词的序列的概率是:
我们可以使用 $unary$ 语言模型方法,通过假设单词的出现是完全独立来将概率分开:
但是我们知道这是不大合理的,因为下一个单词是高度依赖于前面的单词序列的。如果使用上述的语言模型,会让一个无意义的句子可能会具有很高的概率。所以也许我们让序列的概率取决于序列中的单词和其旁边的单词的成对概率。我们称之为 $bigram$ 模型:
但是,这个方法还是有点简单,因为我们
只关心一对邻近的单词,而不是针对整个句子来考虑。但是我们将看到,这个方法会有显著的提升。考虑在词-词共现矩阵中,共现窗口为 1,我们基本上能得到这样的成对的概率。但是,这又需要计算和存储大量数据集的全局信息。
现在我们知道我们能够如何考虑一个序列单词的概率,让我们了解一些可以计算这些概率的模型。
Continuous Bag of Words Model (CBOW)
一个方法是把 ${“The”,”cat”,”over”,”the”,”puddle”}$ 作为上下文和从这些词中能够预测或者生成中心词“$jumped$”。这样的模型我们称之为 $continuous$ $bag\text{-}of\text{-}words$($CBOW$)模型,在这个模型中,我们希望学习两个向量:$v$(输入向量)当词在上下文中;$u$(输出向量)当词是中心词。
我们讨论 $CBOW$ 模型的细节,首先我们设定已知参数。令我们模型的已知参数是 $one\text{-}hot$ 形式的词向量表示。输入的 $one\text{-}hot$ 向量或者上下文我们用 $x^{(c)}$ 表示输出用 $y^{(c)}$ 表示。在 $CBOW$ 模型中,因为我们只有一个输出,因此我们把 $y$ 称为是已知中心词的的 $one\text{-}hot$ 向量。现在让我们定义模型的未知参数。
首先我们对 $CBOW$ 模型作出以下定义:
- $w_{i}$:词汇表 $V$ 中的单词 $i$。
- $\mathcal{V}\in \mathbb{R}^{n\times |V|}$:输入词矩阵。
- $v{i}$:$\mathcal{V}$ 的第 $i$ 列,单词 $w{i}$ 的输入向量表示。
- $\mathcal{U}\in \mathbb{R}^{|V|\times n}$:输出词矩阵。
- $u{i}$:$\mathcal{U}$ 的第 $i$ 行,单词 $w{i}$ 的输出向量表示。
我们创建两个矩阵,$\mathcal{V}\in \mathbb{R}^{n\times |V|}$ 和 $\mathcal{U}\in \mathbb{R}^{|V|\times n}$。其中 $n$ 是嵌入空间的任意维度大小。$\mathcal{V}$ 是输入词矩阵,使得当其为模型的输入时,$\mathcal{V}$ 的第 $i$ 列是词 $w{i}$ 的 $n$ 维嵌入向量。我们定义这个 $n \times 1$ 的向量为 $v{i}$。相似地,$\mathcal{U}$ 是输出词矩阵。当其为模型的输入时,$\mathcal{U}$ 的第 $j$ 行是词 $w{j}$ 的 $n$ 维嵌入向量。我们定义 $\mathcal{U}$ 的这行为 $u{j}$。注意实际上对每个词 $w{i}$ 我们需要学习两个词向量(即输入词向量 $v{i}$ 和输出词向量 $u_{i}$)。
我们将这个模型分解为以下步骤:
我们为大小为 $m$ 的输入上下文生成一个 $one\text{-}hot$ 词向量:$(x^{(c-m)},…,x^{(c-1)},x^{(c+1)},…,x^{(c+m)}\in \mathbb{R}^{|V|})$。
我们从上下文 $(v{c-m}=\mathcal{V}x^{(c-m)},v{c-m+1}=\mathcal{V}x^{(c-m+1)},…,v_{c+m}=\mathcal{V}x^{(c+m)}\in \mathbb{R}^{n})$ 得到嵌入词向量。
对上述的向量求平均值 $\widehat{v}=\frac{v{c-m}+v{c-m+1+…+v_{c+m} }}{2m}\in \mathbb{R}^{n}$。
- 生成一个分数向量 $z = \mathcal{U}\widehat{v}\in \mathbb{R}^{|V|}$。当相似向量的点积越高,就会令到相似的词更为靠近,从而获得更高的分数。
- 将分数转换为概率 $\widehat{y}=softmax(z)\in \mathbb{R}^{|V|}$。这里 $softmax$ 是一个常用的函数。它将一个向量转换为另外一个向量,其中转换后的向量的第 $i$ 个元素是 $\frac{e^{\widehat{y}i} }{\sum{k=1}^{|V|}e^{\widehat{y}k} }$。因为该函数是一个指数函数,所以值一定为正数;通过除以 $\sum{k=1}^{|V|}e^{\widehat{y}k}$ 来归一化向量($\sum{k=1}^{|V|}\widehat{y}_k=1$)得到概率。
- 我们希望生成的概率,$\widehat{y} \in \mathbb{R}^{|V|}$,与实际的概率匹配,$y \in \mathbb{R}^{|V|}$,这是刚好实际的词就是这个 $one\text{-}hot$ 向量。
下图是 CBOW 模型的计算图示:
如果有 $\mathcal{V}$ 和 $\mathcal{U}$,我们知道这个模型是如何工作的,那我们如何学习这两个矩阵呢?这需要创建一个目标函数。一般我们想从一些真实的概率中学习一个概率,信息论提供了一个度量两个概率分布的距离的方法。这里我们采用一个常见的距离/损失方法,交叉熵 $H(\widehat{y}, y)$。
在离散情况下使用交叉熵可以直观地得出损失函数的公式:
上面的公式中,$y$ 是 $one\text{-}hot$ 向量。因此上面的损失函数可以简化为:
$c$ 是正确词的 $one\text{-}hot$ 向量的索引。我们现在可以考虑我们的预测是完美并且 $\widehat{y}{c}=1$ 的情况。然后我们可以计算 $H(\widehat{y}, y)=-1\,log(1)=0$。因此,对一个完美的预测,我们不会面临任何惩罚或者损失。现在我们考虑一个相反的情况,预测非常差并且 $\widehat{y}{c}=0.01$。和前面类似,我们可以计算损失 $H(\widehat{y}, y)=-1\,log(0.01)=4.605$。因此,我们可以看到,对于概率分布,交叉熵为我们提供了一个很好的距离度量。因此我们的优化目标函数公式为: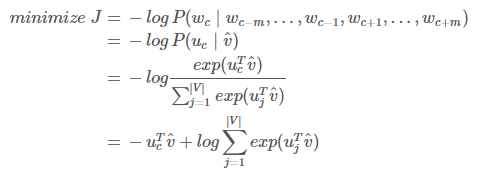
我们使用 $SGD$ 来更新所有相关的词向量 $u{c}$ 和 $v{j}$。$SGD$ 对一个窗口计算梯度和更新参数:
Skip-Gram Model
另外一个创建模型的方法是给定中心词“$jumped$”,模型可以预测或者生成中心词附近的词语 $”The”,”cat”,”over”,”the”,”puddle”$。这样的模型我们称之为 $Skip\text{-}Gram$ 模型。
首先我们对 $Skip\text{-}Gram$ 模型作出以下定义:
- $w_{i}$:词汇表 $V$ 中的单词 $i$。
- $\mathcal{V}\in \mathbb{R}^{n\times |V|}$:输入词矩阵。
- $v{i}$:$\mathcal{V}$ 的第 $i$ 列,单词 $w{i}$ 的输入向量表示。
- $\mathcal{U}\in \mathbb{R}^{|V|\times n}$:输出词矩阵。
- $u{i}$:$\mathcal{U}$ 的第 $i$ 行,单词 $w{i}$ 的输出向量表示。
我们现在来讨论一下 $Skip\text{-}Gram$ 模型。$Skip\text{-}Gram$ 和 $CBOW$ 大体上是一样的,但是我们基本上交换了我们的 $x$ 和 $y$,即 $CBOW$ 中的 $x$ 现在是 $y$,$y$ 现在是 $x$。输入的 $one\text{-}hot$ 向量(中心词)我们表示为 $x$,输出向量为 $y^{(j)}$。我们定义的 $\mathcal{V}$ 和 $\mathcal{U}$ 是和 $CBOW$ 一样的。
我们将这个模型分解为以下步骤:
我们生成中心词的 $one\text{-}hot$ 向量 $x\in \mathbb{R}^{|V|}$。</li>
- 我们对中心词 $v_{c}=\mathcal{V}x\in \mathbb{R}^{|V|}$ 得到词嵌入向量。
- 生成分数向量 $z = \mathcal{U}v_{c}$。
- 将分数向量转化为概率,$\widehat{y}=softmax(z)$。注意 $\widehat{y}{c-m},…,\widehat{y}{c-1},\widehat{y}{c+1},…,\widehat{y}{c+m}$ 是每个上下文词观察到的概率。
- 我们希望我们生成的概率向量匹配真实概率 $y^{(c-m)},…,y^{(c-1)},y^{(c+1)},…,y^{(c+m)}$,$one\text{-}hot$ 向量是实际的输出。
下图是 $Skip-Gram$ 模型的计算图示:
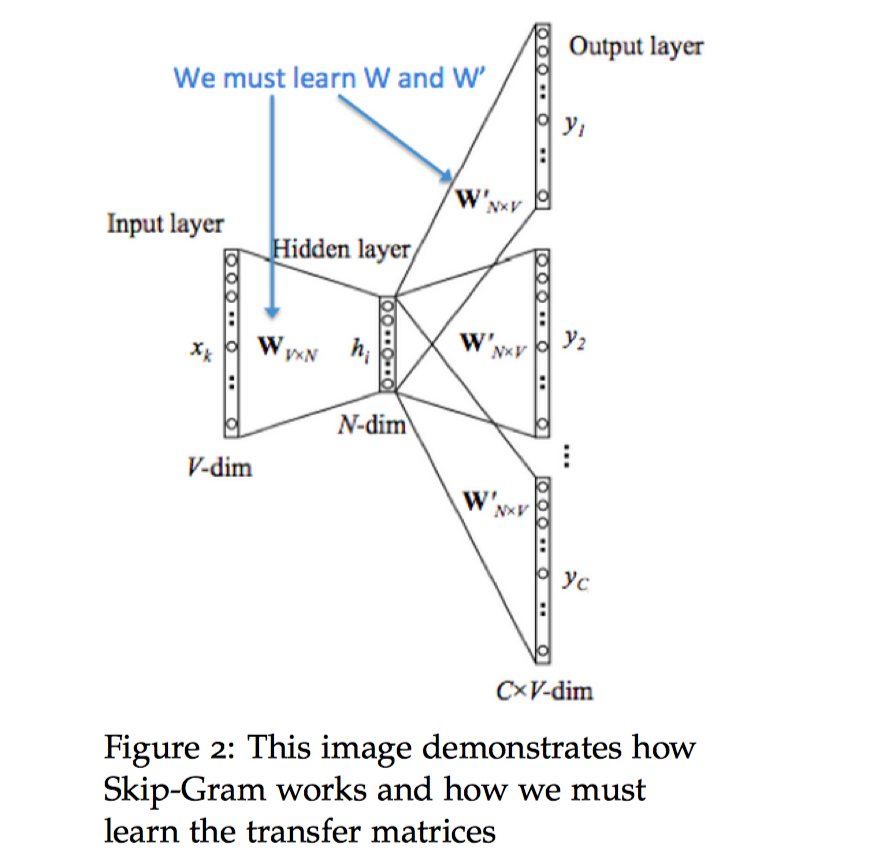
和 $CBOW$ 模型一样,我们需要生成一个目标函数来评估这个模型。与 $CBOW$ 模型的一个主要的不同是我们引用了一个朴素的贝叶斯假设来拆分概率。如果你之前没有了解过,这里可以先放下,这是一个很强(朴素)的条件独立假设。换而言之,给定中心词,所有输出的词是完全独立的。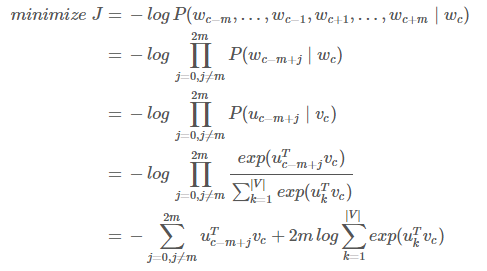
通过这个目标函数,我们可以计算出与未知参数相关的梯度,并且在每次迭代中通过 SGD 来更新它们。
注意
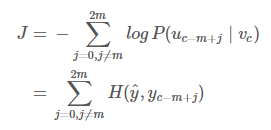
其中 $H(\widehat{y},y{c-m+j})$ 是向量 $\widehat{y}$ 的概率和 $one\text{-}hot$ 向量 $y{c-m+j}$ 之间的交叉熵。
Negative Sampling
让我们再回到目标函数上。注意对 $|V|$ 的求和计算量是非常大的!任何的更新或者对目标函数的评估都要花费 $O(|V|)$ 的时间复杂度。一个简单的想法是不去直接计算,而是去求近似值。
在每一个训练的时间步,我们不去遍历整个词汇表,而仅仅是抽取一些负样例!我们对噪声分布($P_{n}(w)$)“抽样”,这个概率是和词频的顺序相匹配的。我们将负抽样放到问题中,我们只需要更新:
- 目标函数
- 梯度
- 更新规则
$Mikolov$ 在论文《$Distributed$ $Representations$ $of$ $Words$ $and$ $Phrases$ $and$ $their$ $Compositionality.$》 中提出了负采样。虽然负采样是基于 $Skip\text{-}Gram$ 模型,但实际上是对一个不同的目标函数进行优化。考虑一对中心词和上下文词 $(w,c)$。这词对是来自训练数据集吗?我们通过 $P(D=1\mid w,c)$ 表示 $(w,c)$ 是来自语料库。相应地,$P(D=0\mid w,c)$ 表示 $(w,c)$ 不是来自语料库。首先,我们对 $P(D=1\mid w,c)$ 用 $sigmoid$ 函数建模:
现在,我们建立一个新的目标函数,如果中心词和上下文词确实在语料库中,就最大化概率 $P(D=1\mid w,c)$,如果中心词和上下文词确实不在语料库中,就最大化概率 $P(D=0\mid w,c)$。我们对这两个概率采用一个简单的极大似然估计的方法(这里我们把 $\theta$ 作为模型的参数,在我们的例子是 $\mathcal{V}$ 和 $\mathcal{U}$)。
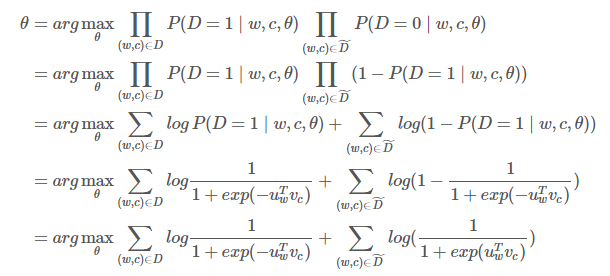
注意最大化似然函数等同于最小化负对数似然:
注意 $\widetilde{D}$ 是“假的”或者“负的”语料。例如我们有句子类似“$stock\;boil\;fish\;is\;toy$”,这种无意义的句子出现时会得到一个很低的概率。我们可以从语料库中随机抽样出负样例 $\widetilde{D}$。
对于 $Skip\text{-}Gram$ 模型,我们对给定中心词 $c$ 来观察的上下文单词 $c-m+j$ 的新目标函数为
对 $CBOW$ 模型,我们对给定上下文向量 $\widehat{v}=\frac{v{c-m}+v{c-m+1}+…+v{c+m} }{2m}$ 来观察中心词 $u{c}$ 的新的目标函数为
在上面的公式中,${\widetilde{u}{k}\mid k=1…K}$ 是从 $P{n}(w)$ 中抽样。有很多关于如何得到最好近似的讨论,从实际效果看来最好的是指数为 $3/4$ 的 $Unigram$ 模型。那么为什么是 $3/4$?下面有一些例如可能让你有一些直观的了解:

“$bombastic$”现在被抽样的概率是之前的三倍,而“$is$”只比之前的才提高了一点点。
Hierarchical Softmax
$Mikolov$ 在论文《$Distributed$ $Representations$ $of$ $Words$ $and$ $Phrases$ $and$ $their$ $Compositionality.$》 中提出了 $hierarchical$ $softmax$,相比普通的 $softmax$ 这是一种更有效的替代方法。在实际中,$hierarchical$ $softmax$ 对低频词往往表现得更好,负采样对高频次和较低维度向量表现得更好。
$Hierarchical$ $softmax$ 使用一个二叉树来表示词表中的所有词。树中的每个叶结点都是一个单词,而且只有一条路径从根结点到叶结点。在这个模型中,没有词的输出表示。相反,图的每个节点(根节点和叶结点除外)与模型要学习的向量相关联。
在这个模型中,给定一个向量 $w{i}$ 的下的单词 $w$ 的概率 $p(w\mid w{i})$,等于从根结点开始到对应 $w$ 的叶结点结束的随机漫步概率。这个方法最大的优势是计算概率的时间复杂度仅仅是 $O(log(|V|))$,对应着路径的长度。
下图是 $Hierarchical$ $softmax$ 的二叉树示意图:
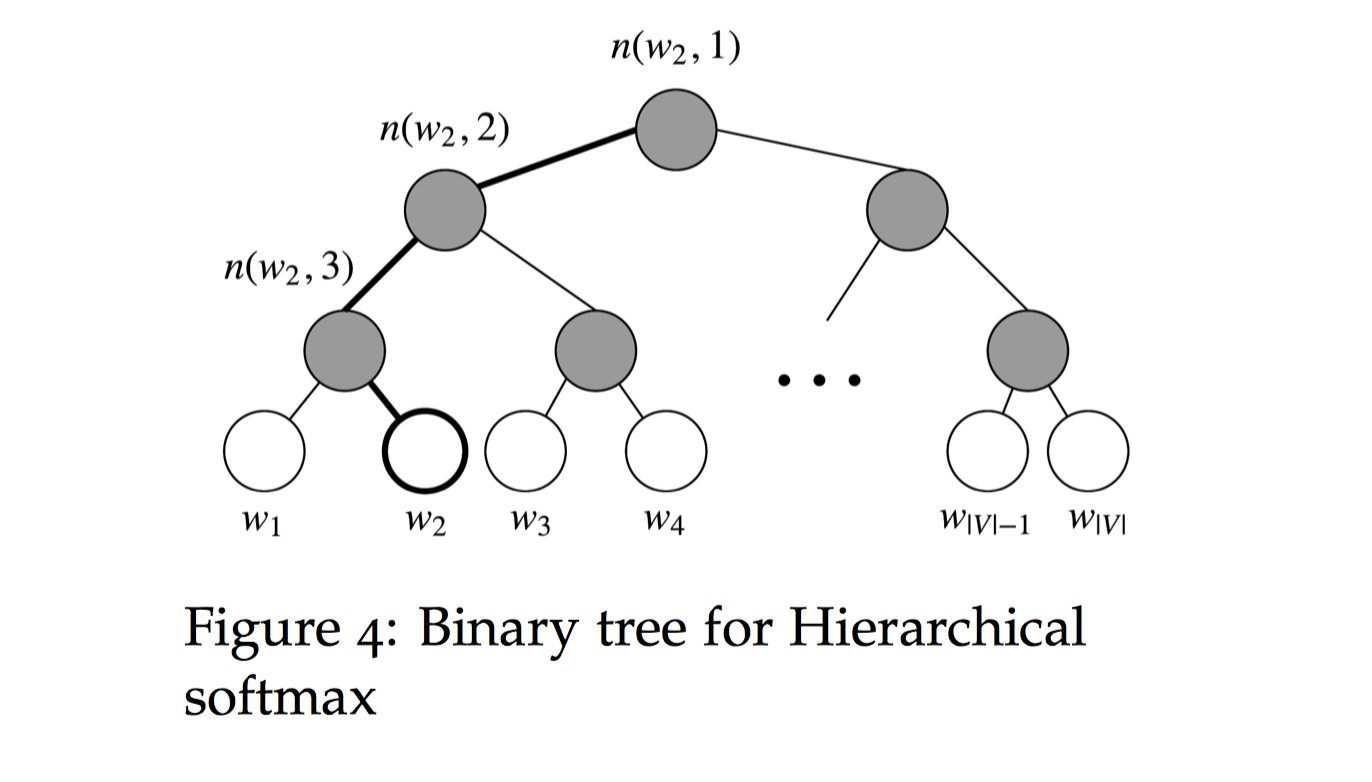
让我们引入一些概念。令 $L(w)$ 为从根结点到叶结点 $w$ 的路径中节点数目。例如,上图中的 $L(w{2})$ 为 $3$。我们定义 $n(w,i)$ 为与向量 $v{n(w,i)}$ 相关的路径上第 $i$ 个结点。因此 $n(w,1)$ 是根结点,而 $n(w,L(w))$ 是 $w$ 的父节点。现在对每个内部节点 $n$,我们任意选取一个它的子节点和定义为 $ch(n)$(一般是左节点)。然后,我们可以计算概率为
其中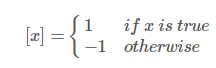
和 $\sigma(\cdot)$ 是 $sigmoid$ 函数。
这个公式看起来非常复杂,让我们细细梳理一下。
首先,我们将根据从根节点 $(n(w,1))$ 到叶节点 $(w)$ 的路径的形状来计算相乘的项。如果我们假设 $ch(n)$ 一直都是 $n$ 的左节点,然后当路径往左时 $[n(n(w,j+1)=ch(n(w,j))]$ 的值返回 $1$,往右则返回 $0$。
此外,$[n(n(w,j+1)=ch(n(w,j))]$ 提供了归一化的作用。在节点 $n$ 处,如果我们将去往左和右节点的概率相加,对于 $v{n}^{T}v{w_{i} }$ 的任何值则可以检查,
归一化也保证了 $\sum{w=1}^{|V|}P(w\mid w{i})=1$,和在普通的 $softmax$ 是一样的。
最后我们计算点积来比较输入向量 $v{w{i} }$ 对每个内部节点向量 $v{n(w,j)}^{T}$ 的相似度。下面我们给出一个例子。以上图中的 $w{2}$ 为例,从根节点要经过两次左边的边和一次右边的边才到达 $w{2}$,因此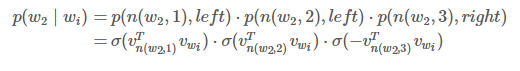
我们训练模型的目标是最小化负的对数似然 $-log\,P(w\mid w{i})$。不是更新每个词的输出向量,而是更新更新二叉树中从根结点到叶结点的路径上的节点的向量。该方法的速度由构建二叉树的方式确定,并将词分配给叶节点。$Mikolov$ 在论文《$Distributed$ $Representations$ $of$ $Words$ $and$ $Phrases$ $and$ $their$ $Compositionality.$》 中使用的是赫夫曼树,在树中分配高频词到较短的路径。
CS224n自然语言处理与深度学习 Lecture Notes One