Tensorflow 之 chinese_hand_writing
识别手写汉字要把识别手写洋文难上很多。
首先,英文字符的分类少,总共10+26*2;而中文总共50,000多汉字,常用的就有3000多。其次,汉字有书法,每个人书写风格多样。
数据来源
手写汉字数据集: CASIA-HWDB
下载HWDB1.1数据集:1
2
3wget http://www.nlpr.ia.ac.cn/databases/download/feature_data/HWDB1.1trn_gnt.zip
# zip解压没得说, 之后还要解压alz压缩文件
wget http://www.nlpr.ia.ac.cn/databases/download/feature_data/HWDB1.1tst_gnt.zip
注意HWDB1.1trn_gnt.zip解压出来的alz还要继续解压,这个alz真是难以捉摸。。。
分析数据
- 数据大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import os
import numpy as np
import struct
train_data_dir = "HWDB1.1trn_gnt"
test_data_dir = "HWDB1.1tst_gnt"
# 读取图像和对应的汉字
def read_from_gnt_dir(gnt_dir=train_data_dir):
def one_file(f):
header_size = 10
while True:
header = np.fromfile(f, dtype='uint8', count=header_size)
if not header.size: break
sample_size = header[0] + (header[1]<<8) + (header[2]<<16) + (header[3]<<24)
tagcode = header[5] + (header[4]<<8)
width = header[6] + (header[7]<<8)
height = header[8] + (header[9]<<8)
if header_size + width*height != sample_size:
break
image = np.fromfile(f, dtype='uint8', count=width*height).reshape((height, width))
yield image, tagcode
for file_name in os.listdir(gnt_dir):
if file_name.endswith('.gnt'):
file_path = os.path.join(gnt_dir, file_name)
with open(file_path, 'rb') as f:
for image, tagcode in one_file(f):
yield image, tagcode
# 统计样本数
train_counter = 0
test_counter = 0
for image, tagcode in read_from_gnt_dir(gnt_dir=train_data_dir):
tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')
train_counter += 1
for image, tagcode in read_from_gnt_dir(gnt_dir=test_data_dir):
tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')
test_counter += 1
# 样本数
print(train_counter, test_counter)
509733 223991
训练集:509733,测试集:223991
- 画个图看看
把刚才的image和tagcode_unicode拎回来
1 | %matplotlib inline |
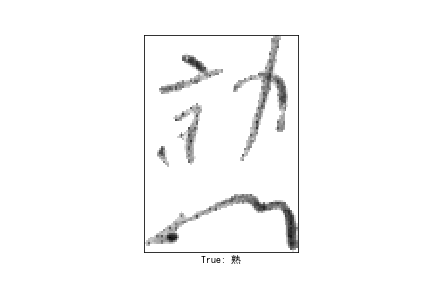
本来是黑底白字,实在看不下去。。。用255-image换了一下颜色
参考
Tensorflow 之 chinese_hand_writing