Targeted Supervised Contrastive Learning for Long-Tailed Recognition
基本信息
标题、时间、会议、领域、code、paper 链接
题目:Targeted Supervised Contrastive Learning for Long-Tailed Recognition
来源:CVPR 2022
Code: https://github.com/LTH14/targeted-supcon
相关背景
研究问题
真实世界中的数据往往会表现出非常不均衡的数据分布问题,头部类别主导训练过程,挤压少数类别分布空间。
以往方案
常见的优化方法有:
- data resample: 数据重采样,对尾部样本进行重采样,使其和头部样本的数量分布接近。
- loss re-weight: 增加尾部数据的权重。
但这些方法增加了尾部样本的出现次数或出现权重,过度拟合了尾部的样本,会牺牲头部类别识别效果。从而损害了学习到的特征质量。
ICLR 2021 的一篇论文 Exploring Balanced Feature Spaces for Representation Learning 提出了 KCL 的方法,是一种借鉴监督学习来进行分类的方法,可以在长尾数据集上有比较好的效果。
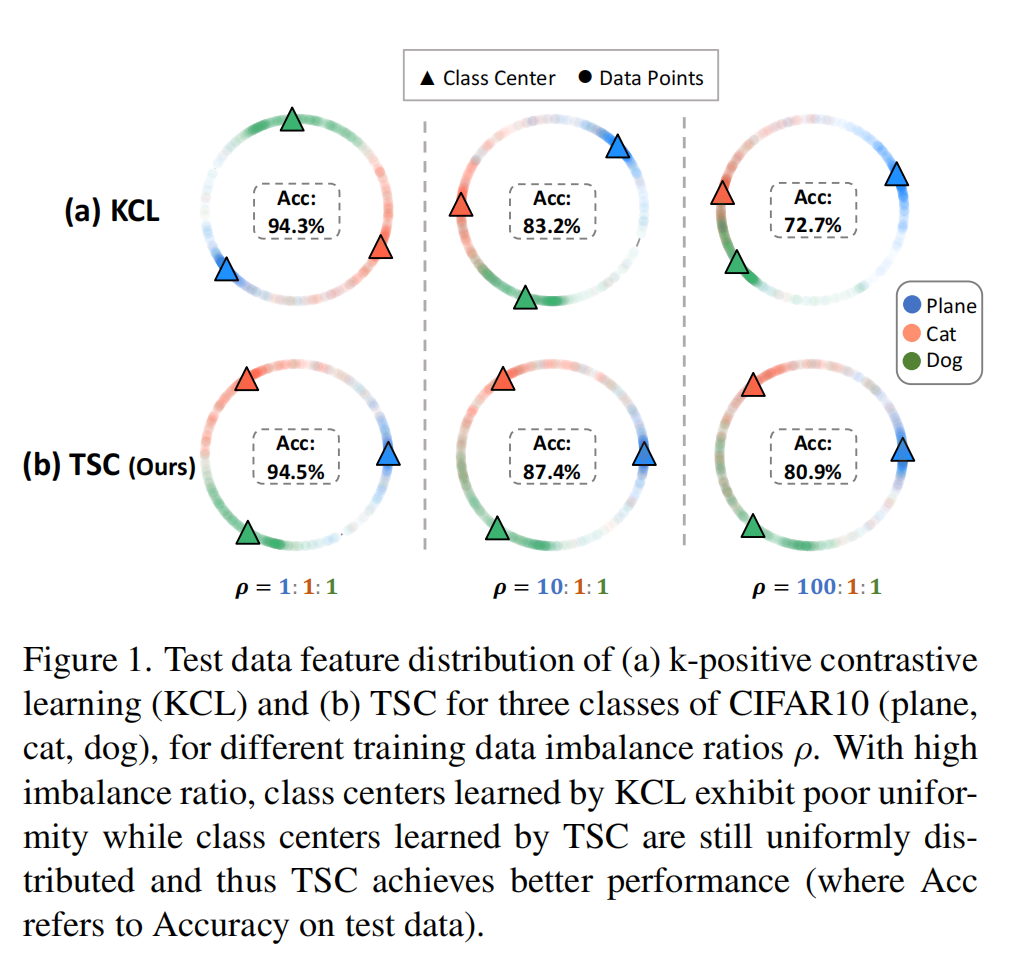
理想的对比学习算法可以产出分布非常均匀的 embedding,也就是每个类别的 embedding 在超球面均匀的的分布,相互之间的距离尽可能的远。
但在数据分布不均匀时,头部标签会挤压尾部标签的 embedding 空间,使头部标签占据更广泛的区域。
动机
本文提出了一种更平衡的表征方法,同时能够学习到统一的特征空间,使长尾分布的数据在特征空间能够更加均匀的分布。实现方式是通过预先指定的 target position, 让 embedding 向着对应 target 方向移动,从而确保分布永远是均匀的(因为位置已经被提前设计好了,不管数据分布怎么变,target是不变了)。
实现步骤
Target Generation
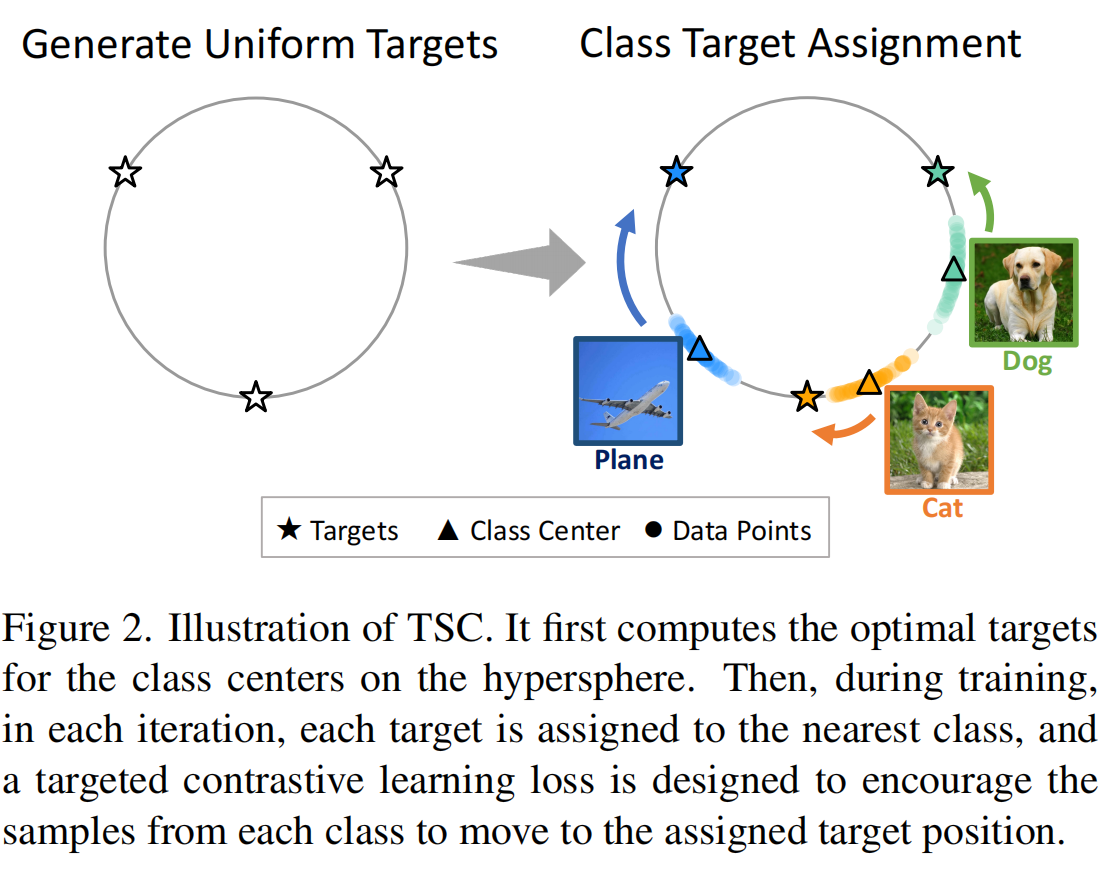
第一步构造目标数据中心,理想的类别位置应当是均匀分布的,也就是说 $\sum{t_i}=0$。即,每个 $t_i$ 离其余的 $t_j$ 越远越好,并设计如下的损失函数和实现代码,用于确定 C classes 的 target 位置。

进入到 loss 方程的 embedding 均 norm 过,那么如果方向完全一致,$t_i^T·t_j$ 为1,最差的情况下就是方向完全不一致,此时为 -1 。
$\sum\limits^C_{j=1}e^{t_j^T·t_j}$ 的结果必然是 $>e^C$ 的,因为 $t_j$ (j 取了所有的 class) 是包含 $t_i$ 的,所以 $\exists t_i^T·t_j >= 1$ ,最后整个 loss 也是总大于 1 的。 $t_i$ 和 $t_j$ 距离越远,那么乘积就越小,最后相加的结果就越小,即可以推导出 loss 越小。实现了所有 class 间距最大的目标。
Matching-Traing Scheme
在获得了 target 位置后,需要将类别标签和 target 的位置进行一一对应。一种方法是将类标签随机的分配到 target 位置,但这会导致模型的语义表征效果比较差。
比如左侧随机分配的 embedding 就要明显差于右侧 embedding 的分布,

$c_i$ 第 i 组特征的中心位置,定义如下算法用于计算 $c_i$ 和 target 之间的距离,并使其距离最小化。这里使用到了一个非常古老的匈牙利算法来进行 target 和 class kernel 的分配。

在理想情况下,语义彼此接近的类应当会被分配到彼此距离也很接近的 target 位置。
训练的 loss
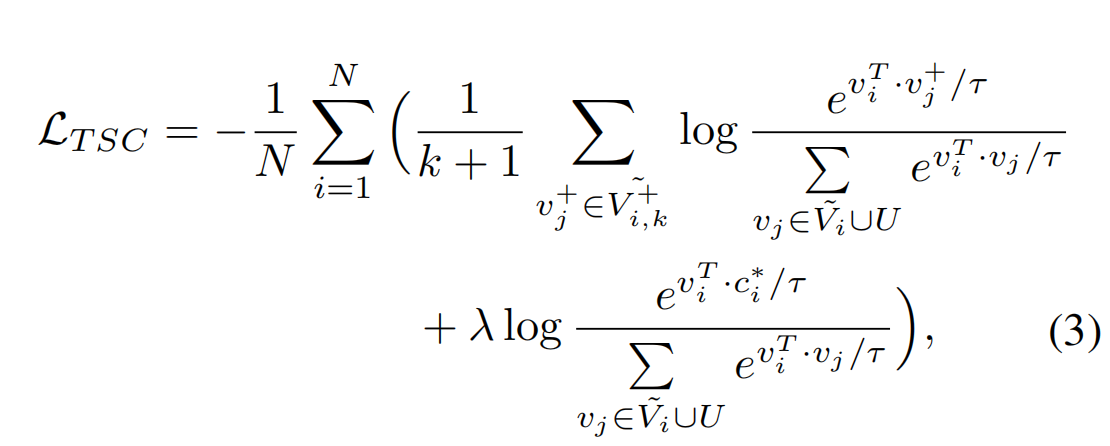
- N是一个batch中样本的数量
- $v_i$表示$x_i$的特征向量
- $\widetilde{v}_i$表示有数据增强$x_i$产生的特征
- $y_i$ 是 $x_i$ 的类别标签
- $V_i$表示一个batch中除去$v_i$的特征向量的其他特征向量集合(正负样本都有)
- $V_{i,k}^+$ 是除了$v_i$之外其余的与$v_i$为同一类的图像集合
- $\widetilde{V}_i$ 表示数据增强 $x_i$ 并 $V_i$ 的集合
- $\widetilde{V}{i,k}^+$ 表示数据增强 $x_i$ 并 $V{i,k}^+$ 的集合(同一类别的其他数据 和 数据增强后的样本)
- U是一组预计算target的集合
- $c_i$ 是 $v_i$ 分到的锚点
- λ为权重
损失分为两个部分,第一个部分是标准的 KCL 损失函数,第二个部分的目的是使样本靠近自己所分配的 target,并远离其他的 target。
在训练过程中,实时将 Target 位置分配给类,并设计有针对性的监督对比损失,让每个类的样本移动到指定的 Target 位置。
Targeted Supervised Contrastive Learning for Long-Tailed Recognition