从零开始搭建Hadoop2.7.1的分布式集群
Hadoop2.7.1,Hadoop的环境配置不是特别的复杂,但是确实有很多细节需要注意,不然会造成许多配置错误的情况。尽量保证一次配置正确防止反复修改。
操作环境说明
操作系统
- 操作系统: window10
- cpu: i7-6700k
- 内存:16g
虚拟机版本:VMware12
ssh-keygen -t rsa -C “mmmwhy@qq.com”
材料准备
- ubuntu-14.10-desktop-amd64.iso (Ubuntu 光盘映像)
- hadoop-2.7.1.tar.gz (Hadoop 环境包)
注意:
ubuntu14.04有自带的java,版本是1.7,输入java -version即可查看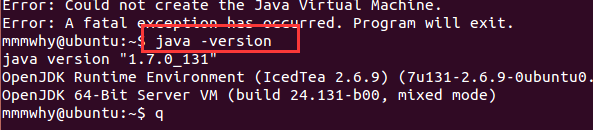
如果没有安装java的话,网上找个安装java的文章即可,比如这篇
搭建开始
搭建开始
Vmware 创建虚拟机
根据Hadoop的调度规则,我们将使用VMware 12 加载 ubuntu….iso来创建三个Ubuntu 虚拟机。创建用典型安装即可。安装位置请选一个足够大的硬盘,预估需要50g。记住这个位置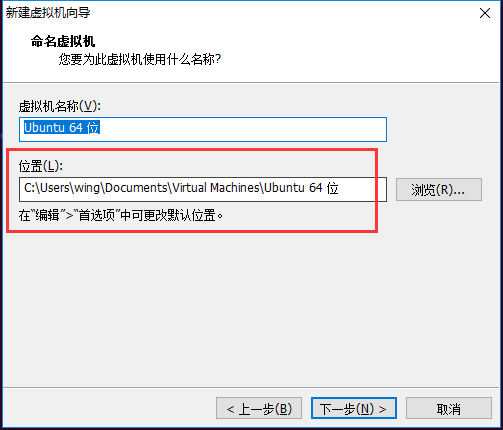
这时我们先创建一个Ubuntu虚拟机,为什么这样稍后解释。
SSH 安装以及配置
先配置ubuntu镜像源
打开软件源文件
1 | sudo gedit /etc/apt/sources.list |
将以下内容替换到源文件(注意在清华大学网站上选择合适自己系统的版本)
1 | # 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释 |
更新软件源
1 | sudo apt-get update |
安装ssh
1 | sudo apt-get install openssh-server |
已有ssh或者安装成功了的输入命令1
ps -e | grep ssh
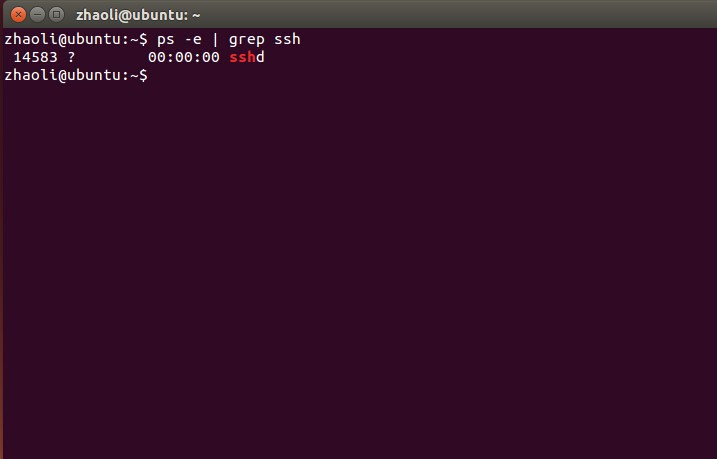
验证SSH是否成功安装输入
1 | ssh localhost |
出现以下提示说明安装成功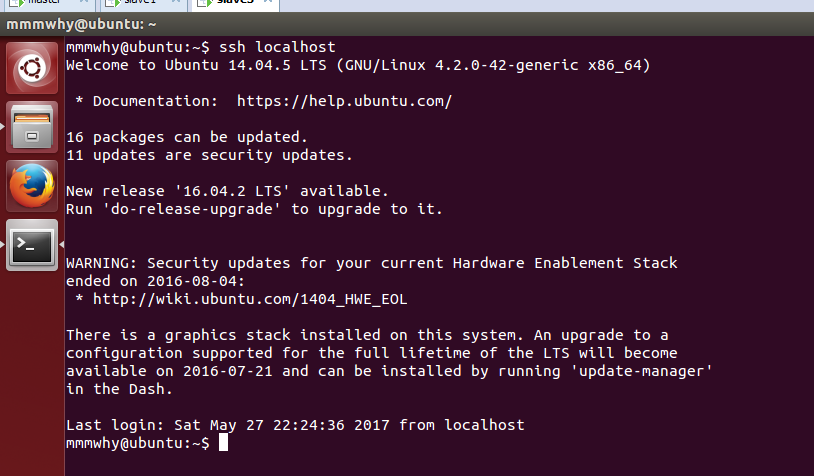
注意,这个时候不是特权模式,特权模式反而会报错,因为我们设置的账户名其实不是root
生成密钥Pair
1 | ssh-keygen -t rsa |
输入后一直回车选择默认即可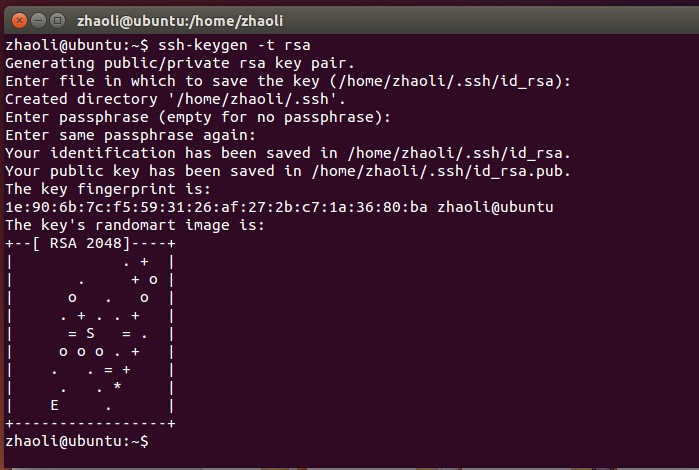
mater主机中输入命令复制一份公钥到home中1
cp .ssh/id_rsa.pub ~/id_rsa_master.pub
复制出两个虚拟机
到开始我们放置虚拟机的位置,复制两份放在旁边,然后用vm直接打开那两个文件夹。
这样可以生成三个一毛一样的虚拟机。
顺便给他们把名字改成各自的角色。
这样做的好处是不需要将之前的步骤重复进行多次,不容易出错。
配置 Hadoop (以下配置将仅仅在master主机上进行 )
- 将解压缩好的hadoop-2.7.1文件夹拷贝到home根目录下面
- 在hadoop-2.7.1文件夹下创建文件,输入
1
2
3
4mkdir hadoop-2.7.1/tmp
mkdir hadoop-2.7.1/hdfs
mkdir hadoop-2.7.1/hdfs/name
mkdir hadoop-2.7.1/hdfs/data - 输入命令查看ip地址 ,三个都要看,找个小本本记下。
1
ifconfig -a
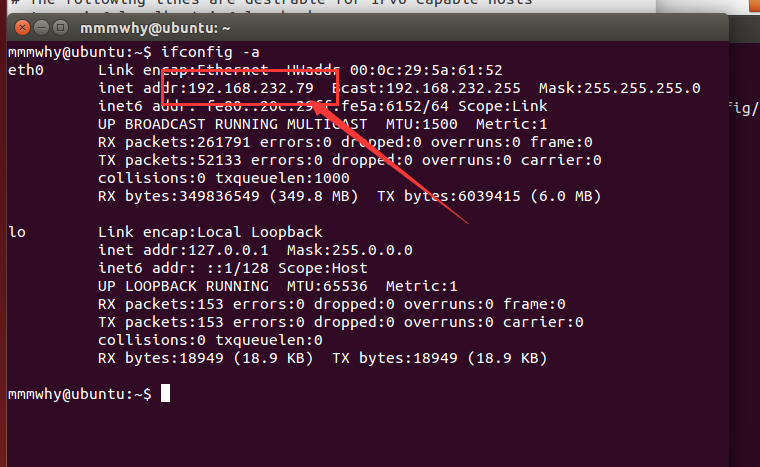
eg. 我所使用的IP地址1
2
3192.168.232.36 master
192.168.232.54 slave1
192.168.232.79 slave2 - 修改hosts
1
sudo gedit /etc/hosts
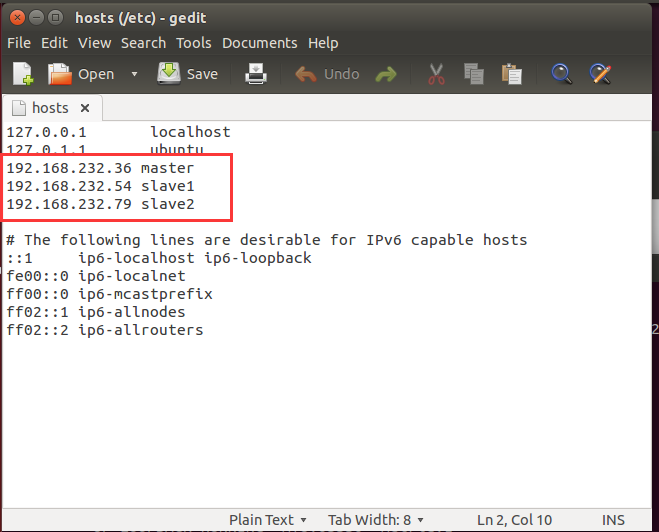
三个ip地址和对应的角色写在hosts内 - 修改hostnamemaster 的改为 master
1
sudo gedit /etc/hostname
slave1 的改为 slave1
slave2 的改为 slave2
修改环境变量
1 | cd ~/hadoop-2.7.1/ |
hadoop-env.sh
1 | gedit etc/hadoop/hadoop-env.sh |
找到JAVA_HOME=… 一行修改为Java HOME的路径1
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
core-site.xml
1 | gedit etc/hadoop/core-site.xml |
在configuration标签中添加1
2
3
4
5
6
7
8
9<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/mmmwhy/hadoop-2.7.1/tmp</value>
</property>
mapred-site.xml
创建并编辑1
2cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
gedit etc/hadoop/mapred-site.xml
在configuration标签中添加1
2
3
4
5
6
7
8
9<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/mmmwhy/hadoop-2.7.1/tmp</value>
</property>
hdfs-site.xml
1 | gedit etc/hadoop/hdfs-site.xml |
在configuration标签中添加1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/mmmwhy/hadoop-2.7.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/mmmwhy/hadoop-2.7.1/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
yarn-site.xml
1 | gedit etc/hadoop/yarn-site.xml |
在configuration标签中添加1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
slaves文件
1 | gedit etc/hadoop/slaves |
删除原有内容,根据配置修改,此处为1
2slave1
slave2
- 分发配置好的hadoop文件夹到slave1, slave2
前提是设置好ssh应该出现一大堆看起来非常厉害的东西。1
2scp -r hadoop-2.7.1 mmmwhy@slave1:~/
scp -r hadoop-2.7.1 mmmwhy@slave2:~/ - 格式化hdfs
进入hadoop home目录1
bin/hdfs namenode -format
- 启动集群启动后分别在master, slave下输入jps查看进程
1
sbin/start-all.sh
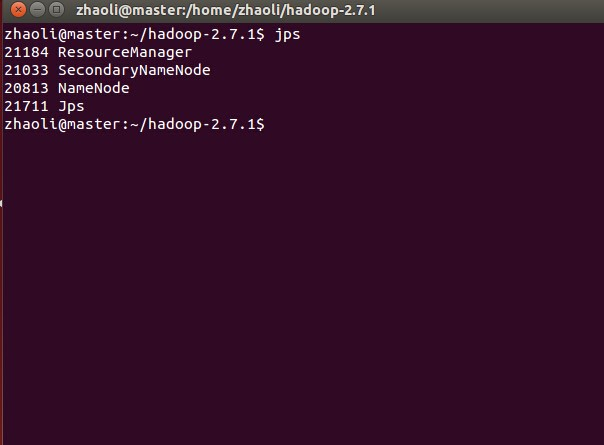
如上则说明启动成功
集群测试
1 | echo hellecho hello world >> in1.txt hadoop >> in2.txt |
然后进入 http://localhost:50070/explorer.html#/usr/input
就可以看到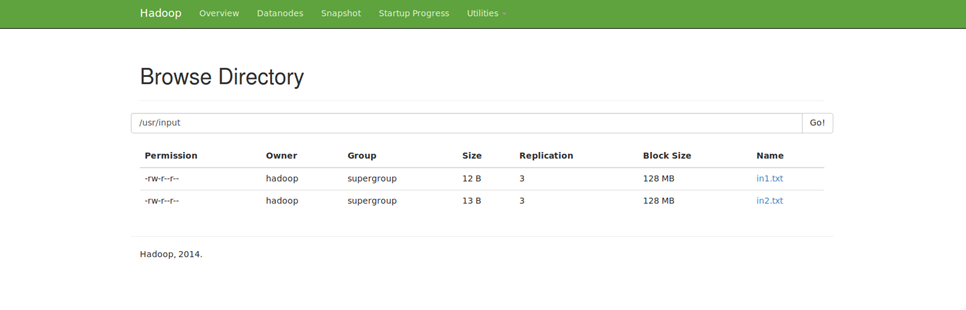
运行wordcount测试
进入hadoop home目录
在hdfs(分布式文件系统)中创建一个名为input的文件夹1
bin/hadoop fs -mkdir /input
查看文件是否被创建1
bin/hadoop fs -ls /
hadoop home 下创建一个inputfile 文件夹,并在inputfile里创建两个文件
in1.txt1
Hello world hello hadoop
in2.txt1
Hello Hadoop hello whatever
上传两个文件进input1
bin/hadoop fs -put inputfile/*.txt /input
查看输入文件是否传入1
bin/hadoop fs -ls /input
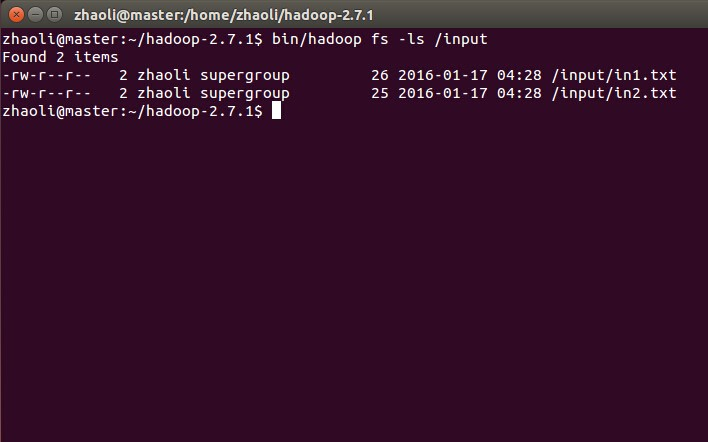
用hadoop jar命令运行Hadoop自带的wordcount1
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input /output
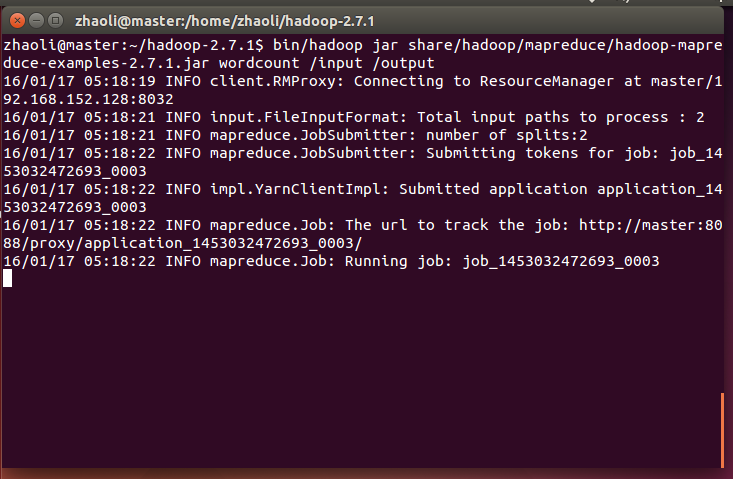
程序开始运行,成功后查看输出文件夹1
2bin/hadoop fs -ls /output
bin/hadoop fs -cat /output/part-r-00000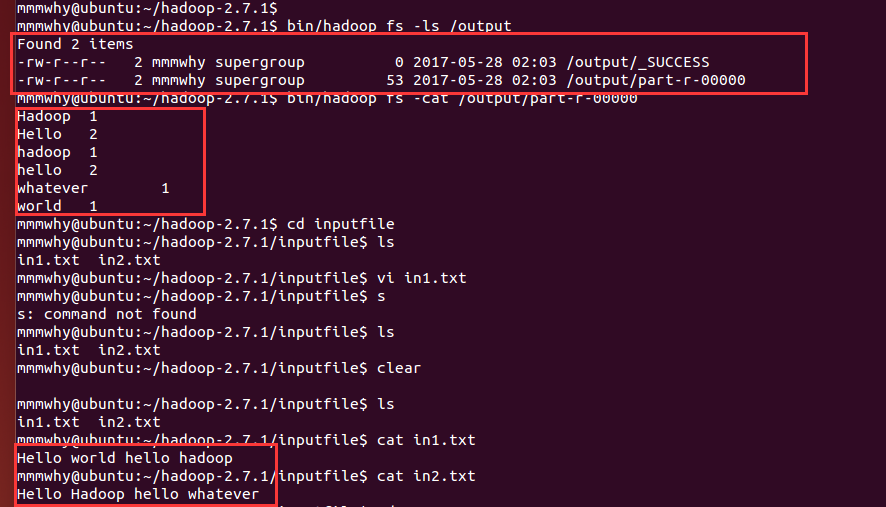
至此hadoop分布式集群配置完成!本文主体内容转自CSDN,原作者写的非常好,但是有一些小问题,做到一半的时候花式报错,因此自己写了一份,修正了其中一些问题。
从零开始搭建Hadoop2.7.1的分布式集群