算法实验(一)
快速排序与背包问题相关算法分析
快速排序
普通快速排序
算法效率:
- 最坏情况下分析:当输入序列是正序或者是反序的时候,效率最坏,这时效率是$Θ(n^2)$
- 最优情况下分析:其他情况下的算法效率趋向于$Θ(nlgn)$
伪代码
对整个数组进行递归排序:快速排序算法的关键是PARTITION过程,它对A[p..r]进行就地重排:1
2
3
4
5QUICKSORT(A,p,r)
if p < r:
q = PARTITION(A,p,r);
QUICKSORT(A,p,q-1);
QUICKSORT(A,q+1,r);1
2
3
4
5
6
7
8
9PARTITION(A,p,r)
x = A[r]
i = p-1
for j = p to r-1// A[j]是待比较的元素
if A[j] ≤ r// 若A[j]比主元小
i = i + 1 // i往后一位(符合,不用替换;不符合i就停在这个地方,等着j过来叫唤)
exchange A[i] with A[j]//倘若A[j]比主元小,其实是不发生交换的。
exchange A[i+1] with A[r]
return i + 1python代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34# coding=utf-8
import datetime
import sys
sys.setrecursionlimit(1000000)
def SET_NUMBER():
l = []
for i in range(0,len(range(1,2000,2)[::-1])-1):
l.append(range(1,2000,2)[::-1][i])
return l
def PARTITION(A,p,r):
x = A[r]
i = p - 1
for j in range(p,r):
if A[j]<=x:
i = i + 1
A[i],A[j]=A[j],A[i]
A[i+1],A[r] = A[r],A[i+1]
return i+1
def QUICKSORT(A,p,r):
if p >= r:
return
q = PARTITION(A,p,r)
QUICKSORT(A,p,q-1)
QUICKSORT(A,q+1,r)
if __name__ == '__main__':
l = SET_NUMBER()
time1 = datetime.datetime.now()
QUICKSORT(l,0,len(l)-1)
time2 = datetime.datetime.now()
print(time2-time1)
随机快速排序
算法效率
我们已经知道,若输入本身已被排序,那么对于快排来说就糟了。那么如何避免这样的情况?一种方法时随机排列序列中的元素;另一种方法时随机地选择主元(pivot)。这便是随机化快速排序的思想,这种快排的好处是:其运行时间不依赖于输入序列的顺序。
经分析, 随机化快排的算法效率是$Θ(nlgn)$
伪代码
下面是分化(Partition)1
2
3
4Random_Partition(vector<T> &A,int p,int q)
int i=rand()%(q-p)+p; //此行与快排不同、加入随机数参数器
Swap(A[i],A[p]); //此行与快排不同、随机选取主元
return Partition(A,p,q);//此次与快速排序一样
随机化快速排序1
2
3
4
5Random_Quick_Sort(vector<T> &A,int p,int q)
if (p<q):
int i=Random_Partition(A,p,q);
Random_Quick_Sort(A,p,i-1);
Random_Quick_Sort(A,i+1,q);
python代码
1 | # coding=utf-8 |
时间效率
- 对于倒序数组
range(1,2000,2)[::-1](1000个数字)- 使用正常快速排序时间为:0:00:00.082566
- 使用随机快速排序时间为:0:00:00.005815
- 对于随机数组
random.randint(0,9999)(重复1000次)- 使用正常快速排序时间为:0:00:00.002974
- 使用随机快速排序时间为:0:00:00.004901
分析性能差异
快速排序的平均时间复杂度为$O(nlogn)$,最坏时间时间可达到$O(n^2)$,最坏情况是当要排序的数列基本有序的时候。根据快速排序的工作原理我们知道,选取第一个或者最后一个元素作为主元,快速排序依次将数列分成两个数列,然后递归将分开的数列进行排序。
当把数列平均分成两个等长的数列时,效率是最高的,如果相差太大,效率就会降低。
我们通过使用随机化的快速排序随机的从数列中选取一个元素与第一个,或者最后一个元素交换,这样就会使得数列有序的概率降低。
所以随机快速排序平均速度是比快速排序要快的,但是因为随机排序需要有设置随机数+交换元素的时间,因此总时间上不如普通快速排序。
背包问题
动态规划知识复习
基本步骤
- 找出最优解的性质,并刻画其结构特征
- 递归地定义最优解的值
- 以自底而上的方式计算出最优值
- 根据计算最优值时得到的信息,构造一个最优解。
若给定问题具有以下性质:
- 最优子结构:如果一个问题的最优解中包含了其子问题的最优解,就说该问题具有最优子结构。当一个问题具有最优子结构时,提示我们动态规划法可能会适用,但是此时贪心策略可能也是适用的。
- 重叠子问题:指用来解原问题的递归算法可反复地解同样的子问题,而不是总在产生新的子问题。即当一个递归算法不断地调用同一个问题时,就说该问题包含重叠子问题。此时若用分治法递归求解,则每次遇到子问题都会视为新问题,会极大地降低算法的效率,而动态规划法总是充分利用重叠子问题,对于每个子问题仅计算一次,把解保存在一个在需要时就可以查看的表中,而每次查表的时间为常数。
0-1背包问题
定义问题
问题:有n个物品,第i个物品价值为$v_i$,重量为$w_i$,其中$v_i$和$w_i$均为非负数,背包的容量为W,W为非负数。现需要考虑如何选择装入背包的物品,使装入背包的物品总价值最大。
该问题以形式化描述如下:
- 目标函数为 :
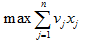
- 约束条件为:
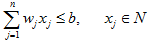
满足约束条件的任一集合(x1,x2,…,xn)是问题的一个可行解,问题的目标是要求问题的一个最优解。考虑一个实例,假设n=5,W=17, 每个物品的价值和重量如下表所示。可将物品1,2和5装入背包,背包未满,获得价值22,此时问题解为你(1,1,0,0,1)。也可以将物品4和5装入背包,背包装满,获得价值24,此时解为(0,0,0,1,1)。
按步骤求解问题
- 找出最优解的性质,并刻画其结构特征
可以将背包问题的求解过程看作是进行一系列的决策过程,即决定哪些物品应该放入背包,哪些物品不放入背包。如果一个问题的最优解包含了物品n,即$xn=1$,那么其余$x_1,x_2,…,x(n-1)$一定构成子问题1,2,…,n-1在容量W-wn时的最优解。如果这个最优解不包含物品n,即$xn$=0,那么其余$x_1,x_2,…,x(n-1)$一定构成子问题1,2,…,n-1在容量W时的最优解。 - 递归定义最优解的值
根据上述分析的最优解的结构递归地定义问题最优解。设c[i,w]表示背包剩余容量为w时,i个物品导致的最优解的总价值。
分为三种情况:- i或者w等于0,没有空间也没有物品的时候;
- 第i的物品的重量已经超过当前空间时;
- 在增加第i个物品和不增加第i个物品之间做出艰难的抉择;
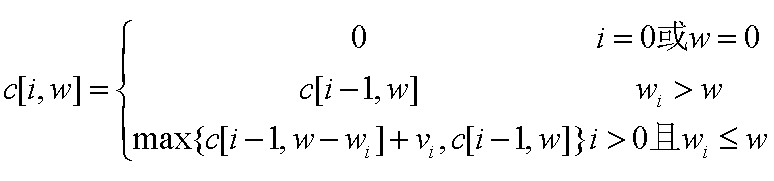
- 以自底而上的方式计算出最优值
伪代码:1
2
3
4
5
6
7
8
9
10BOTTOM-UP-CUT-ROD(p,n)
let r[0..n] be a new array
r[0]= 0
for j = 1 to n
q= -∞
for i = 1 to j
q = max(q, p[i]+r[j-i])
r[j]= q
return r[n]
python代码
1 | #coding:utf-8 |
部分背包问题
题目要求使用贪心算法
- 部分背包问题与0-1背包问题的差别在于:可以带走一部分。即,部分背包问题可带走的物品 是可以 无限细分的。
- 贪心策略是:总是优先选择单位重量下价值最大的物品
具体题目
假设背包可容纳50Kg的重量,物品信息如下:
| 物品 i | 重量(Kg) | 价值 | 单位重量的价值 |
|---|---|---|---|
| 1 | 10 | 60 | 6 |
| 2 | 20 | 100 | 5 |
| 3 | 30 | 120 | 4 |
伪代码
这个看起来就很简单,先装单价最高的1,剩下的地方装2,再剩下的地方装3
我也不知道怎么写伪代码,直接写python吧
C代码
1 |
|