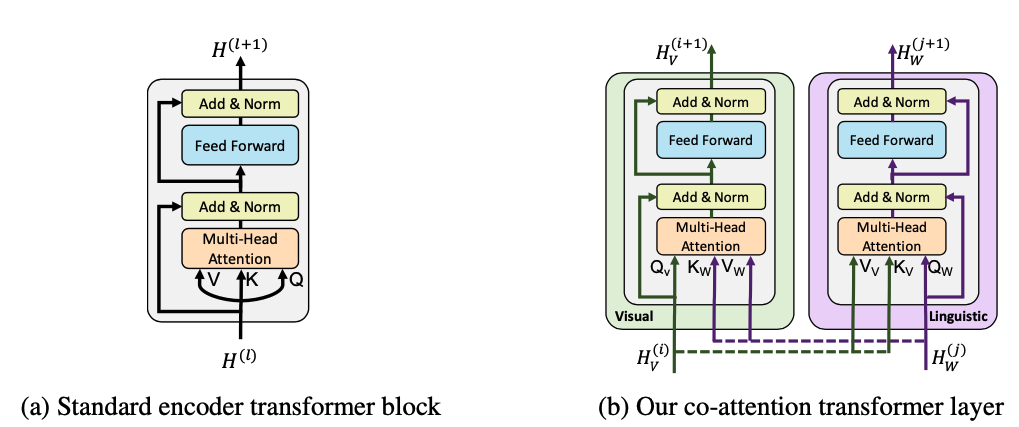
attention 是一种我们常用到的注意力机制。
如果 Query, Key, Value 是由同一个矩阵计算产出,则被称为 self-attention,如上图左所示 。 同样,Query 和 Key + Value 也可以是不同来源的,如上图右的结构所示,self-attention 可以理解为是上右图的一种特殊情况(左右相同嘛)。
标准实现 我们看一下 http://nlp.seas.harvard.edu/2018/04/03/attention.html 这里的标准 attention 实现。
1 2 3 4 5 6 7 8 9 10 11 def attention (query, key, value, mask=None , dropout=None ): "Compute 'Scaled Dot Product Attention'" d_k = query.size(-1 ) scores = torch.matmul(query, key.transpose(-2 , -1 )) \ / math.sqrt(d_k) if mask is not None : scores = scores.masked_fill(mask == 0 , -1e9 ) p_attn = F.softmax(scores, dim = -1 ) if dropout is not None : p_attn = dropout(p_attn) return torch.matmul(p_attn, value), p_attn
基本是按照公式来进行计算的,torch 的实现 与标准实现很相似,但多了一些额外的逻辑处理。
multi_head_attention_forward 代码来自 https://github.com/pytorch/pytorch/blob/1.7/torch/nn/functional.py#L4041
输入参数 首先我们看 qkv 三个输入, batch_size 在第二个维度桑
query: :math:(L, N, E)
key: :math:(S, N, E)
value: :math:(S, N, E)
其中,N 是 batch size 的大小、L 是目标序列的长度 (the target sequence length)、S 是源序列的长度 (the source sequence length)、E 是 embedding 的维度。
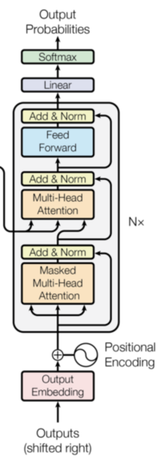
这个模块会出现在下图的3个橙色区域(Attention),所以 the target sequence 并不一定就是指 decoder 输入的序列,the source sequence 也不一定就是 encoder 输入的序列。
更准确的理解是,target sequence 代表多头 attention 当中 q(查询)的序列,source sequence 代表 k(键值)和 v(值)的序列。例如,当 decoder 在做 self-attention 的时候,target sequence 和 source sequence都是它本身,所以此时 L=S,都是 decoder 编码的序列长度。
key_padding_mask: 用来遮蔽以避免pad token的embedding输入。形状要求:(N,S)
举个例子,现在有一个batch,batch_size = 3,长度为4,token表现形式如下:
1 2 3 4 5 [ [‘a’,'b','c','<PAD>'], [‘a’,'b','c','d'], [‘a’,'b','<PAD>','<PAD>'] ]
因为句子的长度不一致,所以短句后边会有多个 <PAD> 。网络其实不应该看到后边的 <PAD> 部分,所以可以生成一个 key_padding_mask 矩阵,用于告诉 multi_head_attention_forward 哪些位置其实是不用看的。 比如这个样子的:
1 2 3 4 5 6 [ [False, False, False, True], [False, False, False, False], [False, False, True, True] ]
从其维度要求 [N,S],可以看出来,该变量主要是给 key 和 value 用的。
attn_mask: 矩阵维度 [L, S] 或者 [N*num_heads, L, S]
在 decoder 阶段,每一个位置应该只能看到当前位置之前的信息。
1 2 3 4 5 6 7 8 9 10 if attn_mask.dim() == 2 : attn_mask = attn_mask.unsqueeze(0 ) if list (attn_mask.size()) != [1 , query.size(0 ), key.size(0 )]: raise RuntimeError("The size of the 2D attn_mask is not correct." ) elif attn_mask.dim() == 3 : if list (attn_mask.size()) != [bsz * num_heads, query.size(0 ), key.size(0 )]: raise RuntimeError("The size of the 3D attn_mask is not correct." ) else : raise RuntimeError("attn_mask's dimension {} is not supported" .format (attn_mask.dim()))
具体代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 tgt_len, bsz, embed_dim = query.size() assert key.size(0 ) == value.size(0 ) and key.size(1 ) == value.size(1 ) head_dim = embed_dim // num_heads assert head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads" scaling = float (head_dim) ** -0.5 q = linear(query, q_proj_weight_non_opt, in_proj_bias) k = linear(key, k_proj_weight_non_opt, in_proj_bias) v = linear(value, v_proj_weight_non_opt, in_proj_bias) q = q * scaling q = q.contiguous().view(tgt_len, bsz * num_heads, head_dim).transpose(0 , 1 ) k = k.contiguous().view(-1 , bsz * num_heads, head_dim).transpose(0 , 1 ) v = v.contiguous().view(-1 , bsz * num_heads, head_dim).transpose(0 , 1 ) attn_output_weights = torch.bmm(q, k.transpose(1 , 2 )) assert list (attn_output_weights.size()) == [bsz * num_heads, tgt_len, src_len] attn_output_weights.masked_fill_(attn_mask, float ("-inf" )) attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len) attn_output_weights = attn_output_weights.masked_fill( key_padding_mask.unsqueeze(1 ).unsqueeze(2 ), float ("-inf" ), ) attn_output_weights = attn_output_weights.view(bsz * num_heads, tgt_len, src_len) attn_output_weights = softmax(attn_output_weights, dim=-1 ) attn_output_weights = dropout(attn_output_weights, p=dropout_p, training=training) attn_output = torch.bmm(attn_output_weights, v) attn_output = attn_output.transpose(0 , 1 ).contiguous().view(tgt_len, bsz, embed_dim)
MultiheadAttention 代码来自 https://github.com/pytorch/pytorch/blob/1.7/torch/nn/modules/activation.py#L831-L985
以 transformer 中的使用为例,MultiheadAttention 类的初始化参数为 embed_dim 和 num_heads, 分别以 512 和 8 , qkv 的 dim 都是 embed_dim,并且 qkv 都是 src ,这时就退化为一个非常典型的 self-attention 了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout) self.linear1 = Linear(d_model, dim_feedforward) self.dropout = Dropout(dropout) self.linear2 = Linear(dim_feedforward, d_model) self.norm1 = LayerNorm(d_model) self.norm2 = LayerNorm(d_model) self.dropout1 = Dropout(dropout) self.dropout2 = Dropout(dropout) src2 = self.self_attn(src, src, src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0 ] src = src + self.dropout1(src2) src = self.norm1(src) src2 = self.linear2(self.dropout(self.activation(self.linear1(src)))) src = src + self.dropout2(src2) src = self.norm2(src)
也就实现了这样一个东西, 代码和图基本可以一一对应起来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout) self.multihead_attn = MultiheadAttention(d_model, nhead, dropout=dropout) self.linear1 = Linear(d_model, dim_feedforward) self.dropout = Dropout(dropout) self.linear2 = Linear(dim_feedforward, d_model) self.norm1 = LayerNorm(d_model) self.norm2 = LayerNorm(d_model) self.norm3 = LayerNorm(d_model) self.dropout1 = Dropout(dropout) self.dropout2 = Dropout(dropout) self.dropout3 = Dropout(dropout) tgt2 = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0 ] tgt = tgt + self.dropout1(tgt2) tgt = self.norm1(tgt) tgt2 = self.multihead_attn(tgt, memory, memory, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0 ] tgt = tgt + self.dropout2(tgt2) tgt = self.norm2(tgt) tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt)))) tgt = tgt + self.dropout3(tgt2) tgt = self.norm3(tgt)
代码基本和图的意图一致
Transformer 由 TransformerEncoder 和 TransformerDecoder 阶段构成,两个函数的写法基本完全一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 self.layers = _get_clones(encoder_layer, num_layers) self.num_layers = num_layers self.norm = norm output = src for mod in self.layers: output = mod(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask) if self.norm is not None : output = self.norm(output)
也就是说,在多层 encoder 的时候,其实下一层 encoder 使用上一层 encoder 的产出结果。 在多层 decoder 的时候,不仅使用到了自己的产出结果,还是用了 encode 产出的 memory 。
比较有意思的是,在多层 decoder 时,一直用的是相同的 memory,并没有说 第一层的 encoder 结果给第一层的 decoder ,第二层的 encoder 结果给第二层的 decoder …….
第二个比较特别的点是,在 multi_head_attention_forward 内,qkv 的维度比较奇怪, batch size 在第二个维度上,这与我们的经验其实是不太相符的,后续代码内也做了转秩来处理这个情况。
第三个点是,外部传进来的 qkv 其实在 multi_head_attention_forward 内,都会被转化为 embed_dim 的长度。 我理解是 因为 qkv 本身就应该 -1 位维度一致的,但可能传入不同维度的矩阵,所以进行了一个处理。但总感觉用处不大的样子。