CNN模型调优策略
CNN应该是最常用的Tensorflow模型,实际使用过程中可能会出现 调用速度过慢的情况。
卷积
关于卷积,在 TensorFlow Tutorial #02 Convolutional Neural Network 有过笔记,这里略微提一下。
理解卷积作用
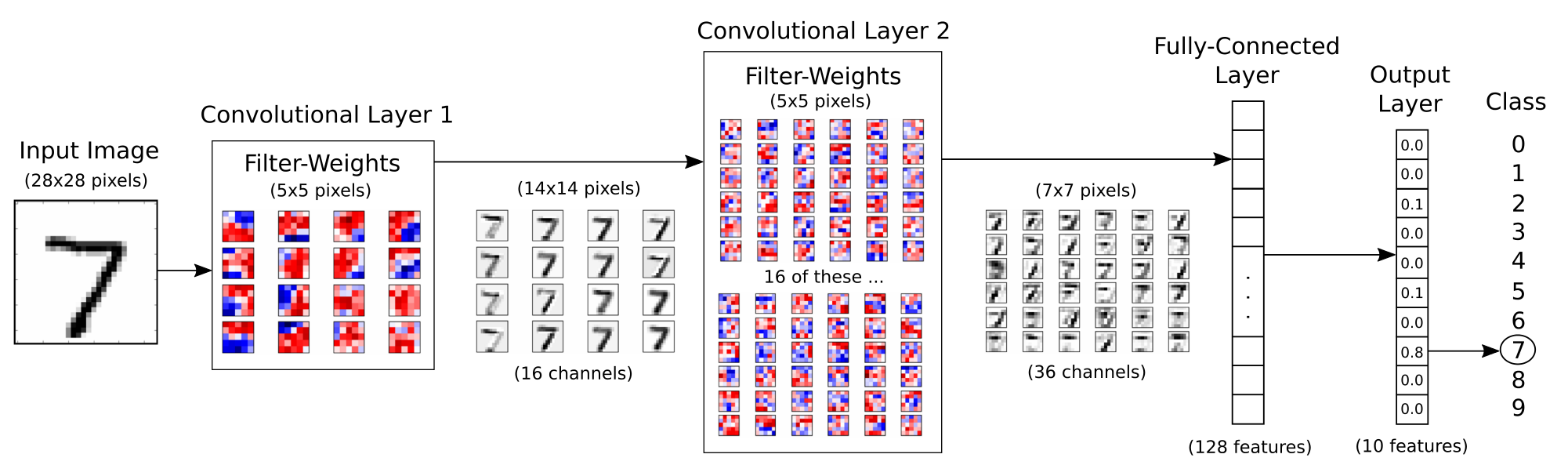
如果原始的图像是最左边的那个7,卷积操作为 16个channel,每个卷积核大小是[5,5],SAME方式,2*2的Max Pooling 一下,所以最终输出是这个样子。
这里因为比较简单,我们可以把卷积核拿出来,单独看看,每个卷积核都画出来的话,我们会发现,每个卷积核有着不同的敏感度。
举个例子有的卷积核可能对直线比较敏感,有的卷积核可能对圆比较敏感,对圆比较敏感的卷积核对识别0就比较有用。
所以卷积核,也就是神经网络的核心思想,其实是希望神经元(这里的卷积核),能够学到一些东西,并记下来。
如果下回再来一个7,那么卷积核发现,呦,这里有两个直线,那他很可能就是7。
神经元也算学到点东西。
当然,大脑其实比这几个神经元复杂得多,所以还有很长的路要走。。。
计算过程
斯坦福提供了一个动图帮助理解卷积的过程

图像 和 卷积核对应位置相乘,然后加起来。
这里,其实是准备了一个滑动窗口,一个一个的滑动过去, 乘->加->凑矩阵
这个滑动的过程是很慢的,如果我们可以想办法转换成矩阵乘法。
然后就可以用eigen mkl 之类的高性能矩阵运算库,直接矩阵运算。
卷积->矩阵
这个图其实不准确,但我实在找不到图了。。。
比如待卷积的矩阵为 1 * 7 * 256 * 1,这里乘1是因为NLP跟图像不一样,是没有高度(或者宽度,比如RGB)。
卷积核为 3 * 256 * 1 * 512
所以出来的结果是 7 * 512,这样一个矩阵。
大概重组流程为:
- 重组输入矩阵
将 7 * 256 重组成 7 * 768 的形式
| 行号 | 内容 |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
第一行是之前第1行和第2行横坐标拼凑结果,前边补0,这里具体参考CNN SAME格式的要求。
变成这个形式
| 行号 | 内容 |
|---|---|
| 1 | 0 1 2 |
| 2 | 1 2 3 |
| 3 | 2 3 4 |
| 4 | 3 4 5 |
| 5 | 4 5 6 |
| 6 | 5 6 7 |
| 7 | 6 7 0 |
- 重组卷积矩阵
3 * 256 * 512 重组成 768 * 512的形式 - 矩阵相乘即可
[7,768] * [768,512] —> [7,512]
逻辑上基本是没有问题的,重组的过程会比较麻烦,注意别算错了。
卷积之提前计算
卷积的本质是将 输入内容进行乘法运算,那么就可以设计出一种办法,提前算好乘法结果,用的时候直接命中即可。
思路如下,在NLP中,常用的汉字大概6000左右,我们增加限制到10000个字。
那么1w个字,对应3个卷积核,也就是最多有3w个结果。
将这3w个结果直接保存下来,调用的时候,就不用做卷积了,直接做命中即可。
应用hash结果计算时间
从数据保存说起
一个矩阵保存在内存中的方式,分为以下两种。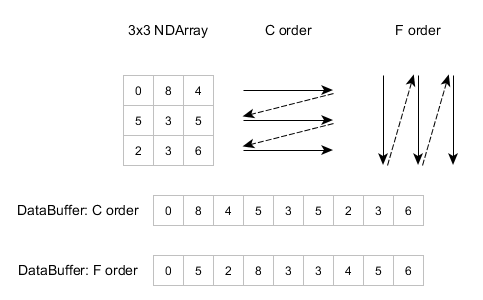
所以如果看看下 内存中的数据
妈耶,那么大的矩阵竟然在内存中是 一字长蛇 保存。
这样就会导致比如说我们要找第999行的数据,程序要一行一行的这么找过去。
数据保存为数组格式
把数据保存成数据格式,可以在找数据的时候,hash表直接命中,不需要一行一行的寻找。
根据测试,在某些重要环节上,如果把矩阵换成 数组 或者vector 与矩阵的结合方式,运算速度可以提高10x