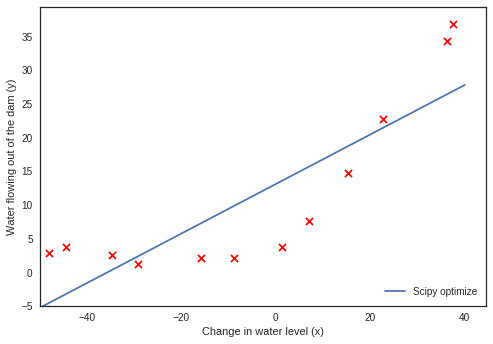
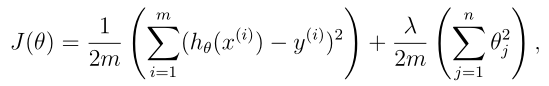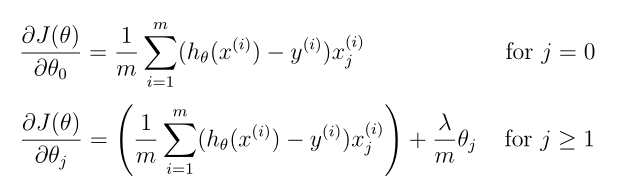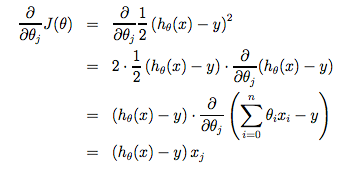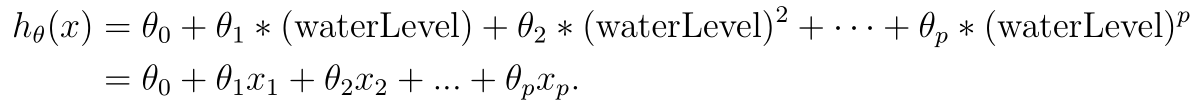plt.scatter(X_train[:,1], y_train, s=50, c='r', marker='x', linewidths=1) plt.xlabel('Change in water level (x)') plt.ylabel('Water flowing out of the dam (y)') plt.ylim(ymin=0);
Regularized Cost function
1 2 3 4 5 6 7 8
deflinearRegCostFunction(theta, X, y, reg): m = y.size h = X.dot(theta) J = (1/(2*m))*np.sum(np.square(h-y)) + (reg/(2*m))*np.sum(np.square(theta[1:])) return(J)
Gradient
1 2 3 4 5 6 7 8
deflrgradientReg(theta, X, y, reg): m = y.size h = X.dot(theta.reshape(-1,1)) grad = (1/m)*(X.T.dot(h-y))+ (reg/m)*np.r_[[[0]],theta[1:].reshape(-1,1)] return(grad.flatten())
deftrainLinearReg(X, y, reg): #initial_theta = np.zeros((X.shape[1],1)) initial_theta = np.array([[15],[15]]) # For some reason the minimize() function does not converge when using # zeros as initial theta. res = minimize(linearRegCostFunction, initial_theta, args=(X,y,reg), method=None, jac=lrgradientReg, options={'maxiter':5000}) return(res)
plt.plot(np.linspace(-50,40), (fit.x[0]+ (fit.x[1]*np.linspace(-50,40))), label='Scipy optimize') #plt.plot(np.linspace(-50,40), (regr.coef_[0]+ (regr.coef_[1]*np.linspace(-50,40))), label='Scikit-learn') plt.scatter(X_train[:,1], y_train, s=50, c='r', marker='x', linewidths=1) plt.xlabel('Change in water level (x)') plt.ylabel('Water flowing out of the dam (y)') plt.ylim(ymin=-5) plt.xlim(xmin=-50) plt.legend(loc=4);
1 2 3 4 5 6 7 8 9 10 11 12
deflearningCurve(X, y, Xval, yval, reg): m = y.size error_train = np.zeros((m, 1)) error_val = np.zeros((m, 1)) for i in np.arange(m): res = trainLinearReg(X[:i+1], y[:i+1], reg) error_train[i] = linearRegCostFunction(res.x, X[:i+1], y[:i+1], reg) error_val[i] = linearRegCostFunction(res.x, Xval, yval, reg) return(error_train, error_val)
plt.plot(np.arange(1,13), t_error, label='Training error') plt.plot(np.arange(1,13), v_error, label='Validation error') plt.title('Learning curve for linear regression') plt.xlabel('Number of training examples') plt.ylabel('Error') plt.legend();
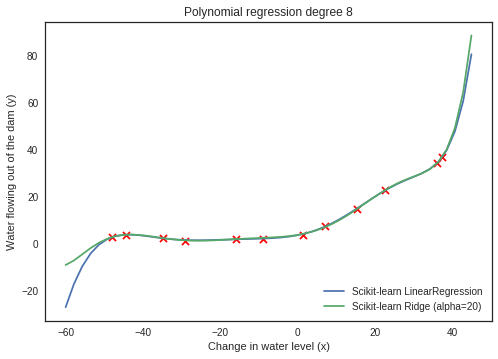
# plot range for x plot_x = np.linspace(-60,45) # using coefficients to calculate y plot_y = regr2.intercept_+ np.sum(regr2.coef_*poly.fit_transform(plot_x.reshape(-1,1)), axis=1) plot_y2 = regr3.intercept_ + np.sum(regr3.coef_*poly.fit_transform(plot_x.reshape(-1,1)), axis=1)
plt.plot(plot_x, plot_y, label='Scikit-learn LinearRegression') plt.plot(plot_x, plot_y2, label='Scikit-learn Ridge (alpha={})'.format(regr3.alpha)) plt.scatter(X_train[:,1], y_train, s=50, c='r', marker='x', linewidths=1) plt.xlabel('Change in water level (x)') plt.ylabel('Water flowing out of the dam (y)') plt.title('Polynomial regression degree 8') plt.legend(loc=4);