全排列算法 — 递归&字典序实现
递归
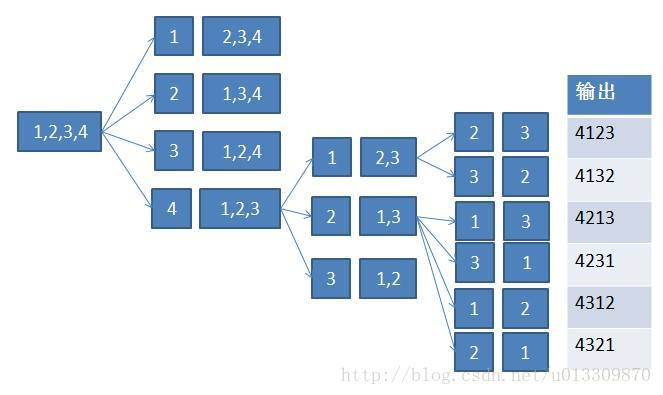
不去重
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| #include<iostream>
#include<vector>
using namespace std;
vector<vector<int>> ans;
void swap(vector<int>& Temp_array,int a,int b) {
int temp = Temp_array[a];
Temp_array[a] = Temp_array[b];
Temp_array[b] = temp;
}
void fullArray(vector<int>& Array, int cursor, int end) {
if (cursor == end) {
ans.push_back(Array);
}
else {
for (int i = cursor; i < end; i++) {
swap(Array, cursor, i);
fullArray(Array, cursor + 1, end);
swap(Array, cursor, i);
}
}
}
int main() {
vector<int> data = {1,2,3};
fullArray(data, 0, 3);
for (vector<int> i: ans) {
for (int j : i) {
cout << j;
}
cout << endl;
}
return 0;
}
|
输出为:
去重的全排列
如果我们输入的是abb,如果第二个字符和第三个交换,就会出现重复的结果。
去重的思路
重复的元素不参与交换
- 由
abb开始交换,可以得到bab(1/2交换)和bba(1/3交换)。
- 由
bab开始交换,又可以得到 bba(2/3交换)
此思路不可行
交换前判断该元素是否已存在已有数内
去重的全排列就是从第一个数字起每个数分别与它后面非重复出现的数字交换。
用编程的话描述就是第i个数与第j个数交换时,要求[i,j)中没有与第j个数相等的数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| #include<iostream>
#include<vector>
using namespace std;
vector<vector<int>> ans;
void swap(vector<int>& Temp_array,int a,int b) {
int temp = Temp_array[a];
Temp_array[a] = Temp_array[b];
Temp_array[b] = temp;
}
//在 Temp_array 数组中,[start,end) 中是否有与 str[end] 元素相同的
bool isswap(vector<int>& Temp_array, int start, int end) {
for (; start < end; start++) {
if (Temp_array[start] == Temp_array[end])
return false;
}
return true;
}
void fullArray(vector<int>& Array, int cursor, int end) {
if (cursor == end) {
ans.push_back(Array);
}
else {
for (int i = cursor; i < end; i++) {
if (isswap(Array, cursor, i)) {
swap(Array, cursor, i);
fullArray(Array, cursor + 1, end);
swap(Array, cursor, i);
}
}
}
}
int main() {
vector<int> data = {1,2,2};
fullArray(data, 0, 3);
for (vector<int> i: ans) {
for (int j : i) {
cout << j;
}
cout << endl;
}
return 0;
}
|
全组合
如果不是求字符的所有排列,而是求字符的所有组合应该怎么办呢?还是输入三个字符 a、b、c,则它们的组合有a b c ab ac bc abc。当然我们还是可以借鉴全排列的思路,利用问题分解的思路,最终用递归解决。不过这里介绍一种比较巧妙的思路 —— 基于位图。
假设原有元素 n 个,则最终组合结果是 2n−1 个。我们可以用位操作方法:假设元素原本有:a,b,c 三个,则 1 表示取该元素,0 表示不取。故取a则是001,取ab则是011。所以一共三位,每个位上有两个选择 0 和 1。而000没有意义,所以是2n−1个结果。
这些结果的位图值都是 1,2…2^n-1。所以从值 1 到值 2n−1 依次输出结果:
001,010,011,100,101,110,111 。对应输出组合结果为:a,b,ab,c,ac,bc,abc。
因此可以循环 1~2^n-1,然后输出对应代表的组合即可。有代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| #include<stdio.h>
#include<string.h>
void Combination(char *str)
{
if(str == NULL)
return ;
int len = strlen(str);
int n = 1<<len;
for(int i=1;i<n;i++) //从 1 循环到 2^len -1
{
for(int j=0;j<len;j++)
{
int temp = i;
if(temp & (1<<j)) //对应位上为1,则输出对应的字符
{
printf("%c",*(str+j));
}
}
printf("\n");
}
}
void main()
{
char str[] = "abc";
Combination(str);
}
|
非递归
由于非递归的方法是基于对元素大小关系进行比较而实现的,所以这里暂时不考虑存在相同数据的情况。
在没有相同元素的情况下,任何不同顺序的序列都不可能相同。不同的序列就一定会有大有小。也就是说,我们只要对序列按照一定的大小关系,找到某一个序列的下一个序列。那从最小的一个序列找起,直到找到最大的序列为止,那么就算找到了所有的元素了。
好了,现在整体思路是清晰了。可是,要怎么找到这里说的下一个序列呢?这个下一个序列有什么性质呢?
T[i]下一个序列T[i+1]是在所有序列中比T[i]大,且相邻的序列。关于怎么找到这个元素,我们还是从一个例子来入手吧。
现在假设序列T[i] = {6, 4, 2, 8, 3, 1},那么我们可以通过如下两步找到它的下一个序列。
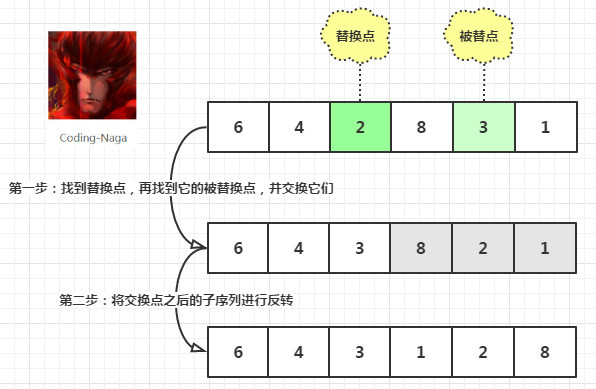
看完上面的两个步骤,不知道大家有没有理解。如果不理解,那么不理解的点可能就在于替换点和被替点的寻找,以及之后为什么又要进行反转上。我们一个一个地解决问题吧。
替换点和被替换点的寻找。替换点是从整个序列最后一个位置开始,找到一个连续的上升的两个元素。前一个元素的index就是替换点。再从替换点开始,向后搜寻找到一个只比替换点元素大的被替换点。(
替换点后面子序列的反转。在上一步中,可以看到替换之后的子序列({8, 2, 1})是一个递减的序列,而替换点又从小元素换成 了大元素,那么与之前序列紧相邻的序列必定是{8, 2, 1}的反序列,即{1, 2, 8}。
这样,思路已经完全梳理完了,现在就是对其的实现了。只是为了防止给定的序列不是最小的,那就需要对其进行按从小到大进行排序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| #include <stdio.h>
#include <stdlib.h>
#include <string.h>
void Swap(char *a, char *b)
{
char t = *a;
*a = *b;
*b = t;
}
void Reverse(char *a, char *b)
{
while (a < b)
Swap(a++, b--);
}
bool Next_permutation(char a[])
{
char *pEnd = a + strlen(a);
if (a == pEnd)
return false;
char *p, *q, *pFind;
pEnd--;
p = pEnd;
while (p != a)
{
q = p;
--p;
if (*p < *q)
{
pFind = pEnd;
while (*pFind <= *p)
--pFind;
Swap(pFind, p);
Reverse(q, pEnd);
return true;
}
}
Reverse(p, pEnd);
return false;
}
int QsortCmp(const void *pa, const void *pb)
{
return *(char*)pa - *(char*)pb;
}
int main()
{
char szTextStr[] = "abc";
printf("%s的全排列如下:\n", szTextStr);
qsort(szTextStr, strlen(szTextStr), sizeof(szTextStr[0]), QsortCmp);
int i = 1;
do {
printf("第%3d个排列\t%s\n", i++, szTextStr);
} while (Next_permutation(szTextStr));
return 0;
}
|
参考
https://blog.csdn.net/lemon_tree12138/article/details/50986990