条件随机场CRF
条件随机场(conditional random field,简称 CRF),是一种鉴别式机率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或是生物序列。
介绍
先上张著名的图 HMM vs CRF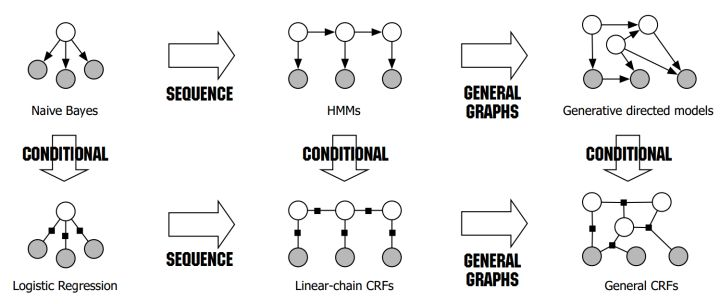
从随机场到马尔科夫随机场
首先,我们来看看什么是随机场。
“随机场”的名字取的很玄乎,其实理解起来不难。
随机场是由若干个位置组成的整体,当给每一个位置中按照某种分布随机赋予一个值之后,其全体就叫做随机场。
还是举词性标注的例子:假如我们有一个十个词形成的句子需要做词性标注。这十个词每个词的词性可以在我们已知的词性集合(名词,动词…)中去选择。当我们为每个词选择完词性后,这就形成了一个随机场。
马尔科夫随机场是随机场的特例,它假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。
从随机场到马尔科夫随机场
对于CRF,我们给出准确的数学语言描述:
设X与Y是随机变量,$P(Y|X)$是给定$X$时$Y$的条件概率分布,若随机变量$Y$构成的是一个马尔科夫随机场,则称条件概率分布$P(Y|X)$是条件随机场
理解了马尔科夫随机场,再理解CRF就容易了。CRF是马尔科夫随机场的特例,它假设马尔科夫随机场中只有$X$和$Y$两种变量,$X$一般是给定的,而$Y$一般是在给定$X$的条件下我们的输出。
这样马尔科夫随机场就特化成了条件随机场。在我们十个词的句子词性标注的例子中,$X$是词,$Y$是词性。因此,如果我们假设它是一个马尔科夫随机场,那么它也就是一个CRF。
从马尔科夫随机场到条件随机场
注意在CRF的定义中,我们并没有要求X和Y有相同的结构。而实现中,我们一般都假设X和Y有相同的结构,即:
$X$ 和 $Y$ 有相同的结构的CRF就构成了线性链条件随机场(Linear chain Conditional Random Fields,以下简称 linear-CRF)。
linear-CRF的数学定义:
设$X =(X_1,X_2,…X_n),\;\;Y=(Y_1,Y_2,…Y_n)$均为线性链表示的随机变量序列,在给定随机变量序列$X$的情况下,随机变量Y的条件概率分布$P(Y|X)$构成条件随机场,即满足马尔科夫性:
$P(Yi|X,Y_1,Y_2,…Y_n) = P(Y_i|X,Y{i-1},Y_{i+1})$
则称P(Y|X)为线性链条件随机场。
线性链条件随机场的参数化形式
对于上一节讲到的linear-CRF,我们如何将其转化为可以学习的机器学习模型呢?这是通过特征函数和其权重系数来定义的。什么是特征函数呢?
节点特征函数
在linear-CRF中,特征函数分为两类,第一类是定义在Y节点上的节点特征函数,这类特征函数只和当前节点有关,记为:
其中$L$是定义在该节点的节点特征函数的总个数,$i$是当前节点在序列的位置。
局部特征函数
第二类是定义在Y上下文的局部特征函数,这类特征函数只和当前节点和上一个节点有关,记为:
其中K是定义在该节点的局部特征函数的总个数,i是当前节点在序列的位置。之所以只有上下文相关的局部特征函数,没有不相邻节点之间的特征函数,是因为我们的linear-CRF满足马尔科夫性。
论是节点特征函数还是局部特征函数,它们的取值只能是0或者1。即满足特征条件或者不满足特征条件。同时,我们可以为每个特征函数赋予一个权值,用以表达我们对这个特征函数的信任度。假设$t_k$的权重系数是$λ_k$,$s_l$的权重系数是$μ_l$,则linear-CRF由我们所有的$t_k,λ_k,s_l,μ_l$共同决定。
解释一下
举个例子,比如有这么一个句子
特征样例:

所以$t_k$和$s_k$是这么来的
linear-CRF的参数化形式
其中,$Z(x)$ 为规范化因子:
回到特征函数本身,每个特征函数定义了一个linear-CRF的规则,则其系数定义了这个规则的可信度。所有的规则和其可信度一起构成了我们的linear-CRF的最终的条件概率分布。
举例
假设输入的都是三个词的句子,即 $X=(X_1,X_2,X_3)$
输出的词性标记为$Y=(Y_1,Y_2,Y_3)$, 其中$Y \in {1(名词),2(动词)}$
解释一下
- t表示第2个或第3个观测值$X_i$为x时,对应的标注y1和y2分别为 名词和动词。
- s表示第1个或第2个观测值$X_i$为x时,它对应的标注很可能为 动词,可能性为 0.5。
求标记(1,2,2)的最可能的标记序列。
位置1初始化
- 如果位置1是名词
- 如果位置1是动词表示第一个位置,名词的概率为1,动词的概率为0.5。
注意,这里没有做 规范化处理,因为没啥必要,反正最后选最大的就行了。
这也符合我们的预期,一般动词做句首比较少。
因为这个问题是一个bp动态规划问题,所以我们需要一个参数来记住走过的路。
位置2
如果位置2是名词
如果位置2是动词
位置2 的两种情况都是从位置1位名词的情况下转移过来的,
位置3
- 如果位置3是动词
- 如果位置3是名词
结果
最终得 $y_3^* =\arg\;max{\delta_3(1), \delta_3(2)}$, 然后倒退回去。
或者(1,2,1),即标注为(名词,动词,名词)
要注意的是,每个位置的概率竟然是加起来的,不是乘起来的,怪不得Tensorflow做了那么妖娆的优化,将时间复杂度降到了$O(n)$
与CRF的比较
举个例子,对于一个标注任务,“我爱北京天安门“,
标注为" s s b e b c e"
HMM
对于HMM的话,其判断这个标注成立的概率为 P= P(s转移到s)P(‘我’表现为s) P(s转移到b)P(‘爱’表现为s) …*P().训练时,要统计状态转移概率矩阵和表现矩阵。
HMM是生成模型, 建立了隐变量(state)和观测量(observation)的联合分布.
CRF
对于CRF的话,其判断这个标注成立的概率为 P= F(s转移到s,’我’表现为s)….F为一个函数,是在全局范围统计归一化的概率而不是像MEMM在局部统计归一化的概率。
CRF是判别模型,因为没有x的知识,无法生成样本,只能判断分类。
判别 vs 生成
数学概念
判别模型:
学习得到条件概率分布P(y|x),即在特征x出现的情况下标记y出现的概率。生成模型:
学习得到联合概率分布$P(x,y)$,即特征x和标记y共同出现的概率,然后求条件概率分布。能够学习到数据生成的机制。
数据要求
生成模型需要的数据量比较大,能够较好地估计概率密度;
而判别模型对数据样本量的要求没有那么多。