ICDE2018 ·《Inf2vec:Latent Representation Model for Social Influence Embedding》
论文来自于ICDE2018, 论文链接,关于影响力最大化的一篇文章。
PPT
Inf2vec-Latent Representation Model for Social.pptx 仅供参考
摘要
作为社会影响传播分析的基本问题,学习影响参数已被广泛研究。提出了大多数现有方法来估计社交网络中每个边缘的传播概率。
然而,由于数据稀疏性,它们不能有效地学习所有边缘的传播参数,特别是对于没有足够观察到的传播的边缘。与传统方法不同,本文引入了一种新的社会影响嵌入问题,即学习节点而不是边缘的参数。节点在低维空间中表示为向量,因此社会影响信息可以由这些向量反映。我们开发了一个新的模型Inf2vec,它结合了当地影响邻域和全球用户相似性来学习表示。我们对两个真实数据集进行了大量实验,结果表明Inf2vec明显优于最先进的基线算法。
介绍
在线社交网络,例如Facebook,Twitter,LinkedIn,Flickr和Digg,是用于传播想法和消息的平台。用户的行为和意见受到社交网络上朋友的高度影响,这被定义为社会影响力。
受各种应用的推动,例如病毒式营销[1],社会影响力研究引起了广泛的研究关注。社会影响研究的一个基本问题是从观察中学习影响参数[2],[3],[4],[5],[6],[7],[8]。我们可以观察用户在社交网络上的一系列动作。
例如,用户喜欢关于Digg的故事 - 这是一个新闻共享网站,然后他们的朋友也可能喜欢这个故事。
根据用户的在线行为,我们的目标是学习参数,以反映社会影响。对社会影响进行建模的过程可以使许多任务受益,例如预测谁将受到社交网络的影响。已经提出了各种方法[2],[3],[4],[9],[10]来学习影响参数,并且大多数方法学习每个边缘的扩散概率。然而,由于传播观察的稀疏性,这些方法不能有效地估计所有边缘的影响参数,尤其是对于没有足够观察到的传播的边缘。此外,所有这些方法仅考虑估计影响参数的社会影响,但不考虑其他因素,例如用户兴趣的相似性。最近提出了网络嵌入[11],[12],[13],[14],[15]来表示潜在的低维空间中的每个用户。网络的结构由学习的用户表示捕获。
受网络嵌入方法的启发,我们研究了一种新的社交影响建模方法。我们不是直接估计每个边缘的传播概率,而是尝试学习每个节点的表示,以便社会影响通过潜在的低维空间中的节点的表示来反映。
这种方法有两个优点。
- 首先,它可以帮助有效地识别用户之间隐藏的影响关系。例如,假设用户u1可以影响用户u3,并且用户u2可以影响用户u3和用户u4,那么用户u1可能也能够影响u4。然而,以前的模型[2],[3]无法明确捕捉到这种关系。
- 其次,它可以缓解稀疏观测数据带来的挑战。特别地,现有模型不能有效地学习边缘的概率而没有观察到影响传播。例如,如果在链接(u,v)上没有观察到社会影响,则很难估计影响概率Puv。相反,嵌入模型可以分别学习节点u和节点v的表示,然后估计u和v之间的扩散关系。
据我们所知,现有的学习影响模型的工作都没有共同捕获影响传播和网络嵌入,以前的工作都没有考虑用户兴趣相似性。 为填补这一空白,我们提出了一个新的研究问题: 社会影响嵌入(social influence embedding)。 该问题旨在有效地将社会影响传播嵌入低维潜在空间。
这个问题的挑战有三个方面。
- 首先,我们需要模拟影响用户在线行为的多个因素,包括社交网络结构,过去的影响力传播以及用户兴趣的相似性。
- 第二,如何根据稀疏的观测传播数据有效地学习节点的表示?
- 第三,学习过程应该是高效的,这样我们才能处理大规模的社交网络。 为了应对这些挑战,我们开发了一种名为Inf2vec的新表示模型来学习社交影响嵌入。
Inf2vec模型的关键是如何从观察到的传播中生成影响上下文,影响上下文是受给定用户影响的一组用户。然而,生成影响上下文是非常重要的,因为我们只能观察用户的操作,但不知道谁确实受到给定用户的影响。在这项工作中,我们考虑两个成分来产生影响背景。
- 首先,我们采用当地影响传播邻域。给定社交网络和一组动作观察,我们提取传播网络,并在传播网络上利用随机游走策略来产生一组用户。这些用户充当给定用户的本地影响上下文。
- 其次,我们考虑用户兴趣的相似性。用户的行为不仅可以受到他的朋友的影响,还可以受到用户个人偏好的影响(在第III节中进行分析)。直观地,具有相似兴趣的用户更可能执行相同的操作。
为了结合用户兴趣相似性的效果,对于给定用户,我们随机地采样执行与全局用户相似性上下文相同的动作的一组用户。通过这两个组成部分,我们能够在学习节点嵌入中纳入三个因素:局部影响上下文反映网络结构和影响传播,而全局用户相似性上下文代表用户兴趣的因素。基于生成的影响上下文,Inf2vec利用word2vec技术[16],[17]来学习社交影响嵌入的表示。
本文主要贡献:
- 我们提出了一个新的框架,用于从观察中学习影响参数,这是社会影响分析的基本问题。具体来说,我们研究了一种新的社会影响嵌入问题,即在低维潜在空间中表示影响传播信息。与大多数先前关于学习影响参数的研究不同,我们学习每个节点的潜在表示,而不是学习每个边缘的传播概率。据我们所知,这是第一个直接利用节点表示来捕捉社会影响的作品。
- 我们提出了一种新的算法Inf2vec来学习节点的表示。该算法的新颖性在于产生影响上下文,其结合了局部影响上下文和全局用户相似性上下文。因此,我们的方法能够包含三个因素:网络结构,影响扩散和用户兴趣的相似性。然而,之前关于学习影响参数的工作都没有考虑用户的兴趣。
- 我们对两个真实数据集进行了大量实验。实证结果表明,Inf2vec明显优于最先进的基线。
SOCIAL INFLUENCE EMBEDDING
本文有两个假设:
如果我们观察到用户u在用户v之前执行了一个动作,并且如果在社交网络中也有一个有向链接(u,v),那么我们假设用户u影响用户v。 该假设的原因是,如果用户v将用户u列为朋友,则用户v可以观看用户u的活动并受用户u的影响。
对于执行相同操作的用户,我们假设他们共享相似的用户兴趣。 这种假设在用户行为分析和推荐系统中被广泛采用[24]。 个人兴趣在用户行为中起着重要作用,用户有不同的兴趣[9]。 通过利用这一假设,我们考虑用户对用户在线行为建模的兴趣。

首先定义了社会影响力对的概念,其次用图展示。
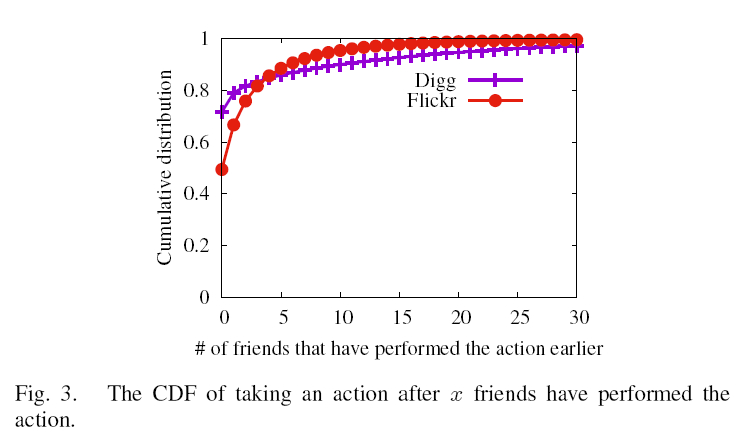
为了研究社交影响对用户在线行为的影响,我们计算在用户之前执行相同操作的朋友数量的累积分布函数(CDF)。 图3显示了Digg和Flickr上的CDF,横坐标为在用户action之前,好友action的数量。 在Digg(相应的Flickr)数据集中,x = 0的CDF为0.7(相应的0.5),这表明70%(相当于50%)的用户在没有朋友影响的情况下进行活动。 同时,30%(相当于50%)的用户在他/她的朋友中至少有一个这样做之后执行了一个动作。 由于用户可以看到他/她的朋友的在线活动,我们假设该用户将受到他的朋友的影响。 这一观察表明,虽然社会影响在决定用户的在线行为中起着重要作用,但用户的行为也受到其他因素的影响。
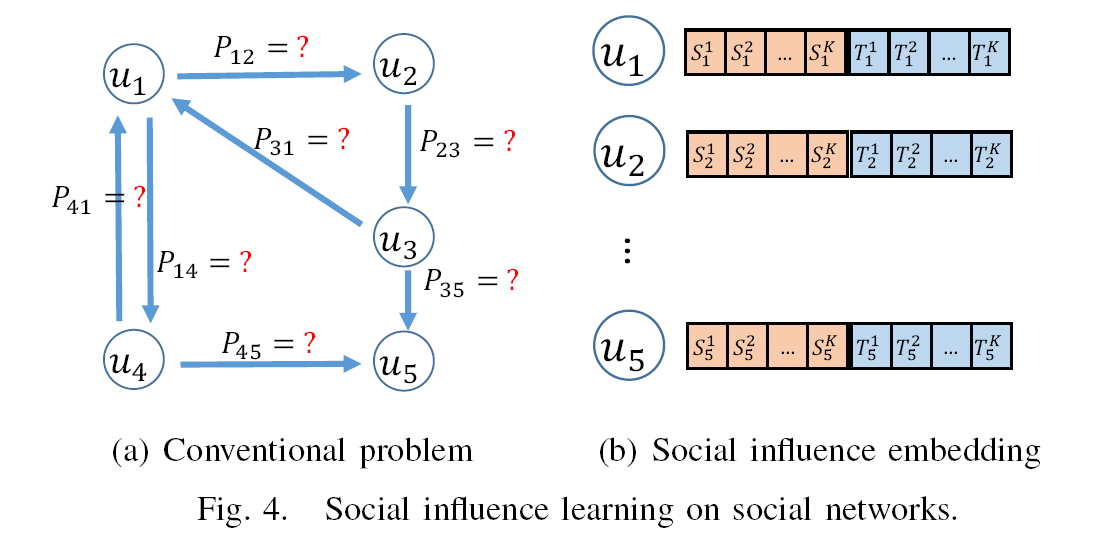
与现有研究不同,本文研究了一个新的研究问题:social influence embedding。
本文的目标是在低维潜在空间中表现社会影响的传播。在这个问题中,本文试图学习| V |的表示给定网络中的节点。social influence embedding 的基本思想如图4(b) 所示,其中我们学习节点的表示:{u1,u2,u3,u4,u5}。
在社交影响嵌入中,两个用户之间的传播关系通过其向量之间的相似性来建模。注意,影响传播是有方向的。为了反映社会影响的方向,用户u在K维空间中有两个向量:Su 表示影响其他用户的能力; Tu表示受其他用户影响的趋势。这里,维度K的数量是可调参数,并且其值是凭经验确定的。
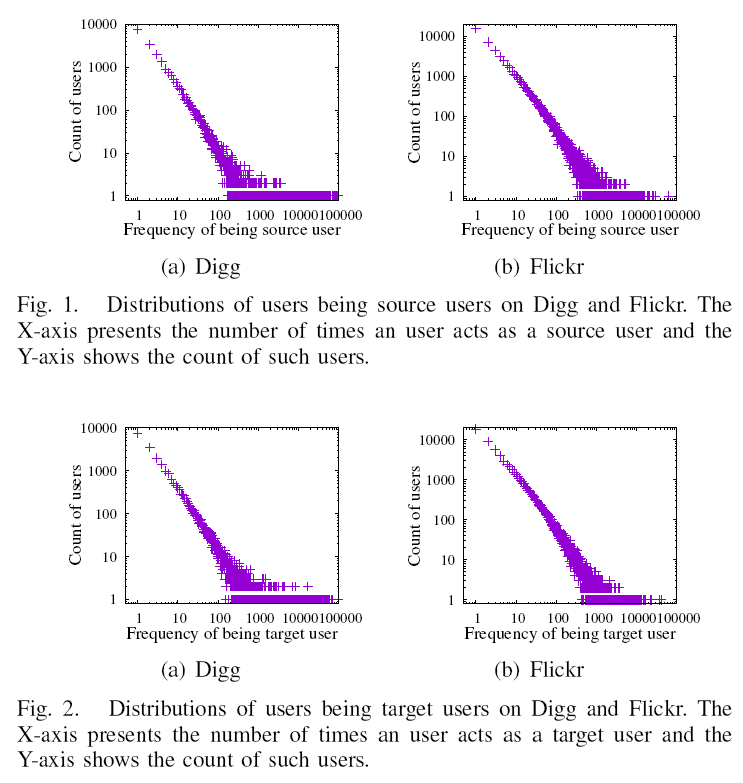

在社会影响力分析中,我们需要考虑每个用户的全局属性。 一方面,直观地说,一些用户,如电影明星和政治家,在社交网络中比普通用户更有影响力。 另一方面,一些用户更倾向于受到他人的影响。 这些直觉可以用图1和图2来解释。但是,这样的全局属性不能通过我们将为每个用户学习的两个潜在向量来反映。 为了更好地模拟社会影响,我们还引入了两个术语:影响能力偏见反映了用户u影响他人的整体能力,整合偏差反映了用户倾向于受到他人的影响[27]。

问题描述为:
- 为每个用户u在K维潜在空间中嵌入Su∈RK和目标嵌入Tu∈RK
- 每个用户u的影响能力偏差bu和一致性偏~bu。
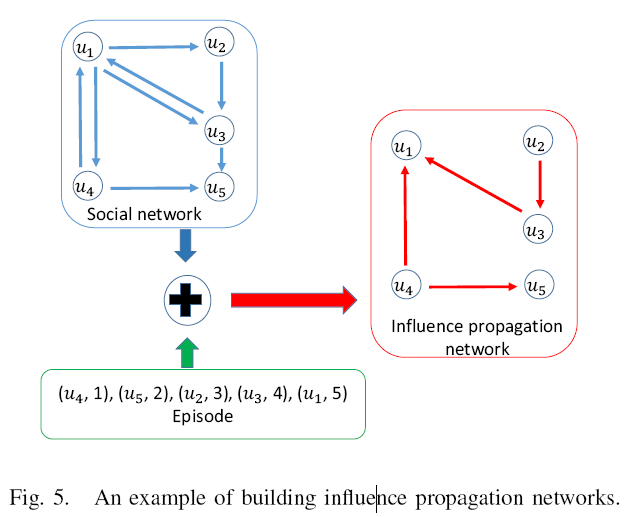
图5说明了获得影响传播网络的idea。
示例社交网络包含5个用户:u1,u2,u3,u4,u5。 每个episode都包含用户的连续动作。
基于社交网络和episode数据,我们提取所有社交影响对。
例如,由于用户u4在用户u5之前执行动作,我们可以获得社交影响对(u4→u5)。 同样,我们获得了其他三个社会影响对:{(u2→u3),(u4→u1),(u3→u1)}。 通过结合这些影响对(paie),我们可以获得影响力传播网络(右边的这个)。
全局用户相似性背景:如图3所示,用户的在线行为并不总是归因于社会影响。
在这项工作中,我们进一步考虑用户偏好相似性来生成影响上下文。用户偏好对于推荐用户在推荐系统中的行为非常重要[24]。用户的在线操作反映了他/她的个性化兴趣。具有相似兴趣的用户更可能具有类似的行为。给定传播网络Gi =(Vi,Ei),Vi中的所有节点都执行了动作i,这意味着这些用户对同一项目感兴趣。但是,现有方法不考虑这些信息。
为了解决这个问题,我们在生成影响上下文 Ciu 时考虑用户兴趣相似性。为了捕获用户兴趣相似性,我们还考虑执行相同操作的用户。给定传播网络中的用户u, 我们在Vi中随机抽样一组用户。本地影响上下文仅反映本地邻域,而类似用户的样本可以反映全局上下文。
因此,我们将这些抽样用户视为全局用户相似性上下文。

第二行采用随机游走的方式计算Local Influence Context,第三行采用随机抽样的方式获得全局用户相似context,以a和1-a的权重想加。

算法2总结了所提出的Inf2vec方法。
它包含两部分:第一部分(第3-8行)生成社会影响上下文,第二部分(第9-17行)为每个用户根据生成的影响上下文学习参数。
Inf2vec算法第1行初始化参数,对于动作日志中的每一集Di,我们通过算法1(第6行)中描述的随机过程获得传播网络(Vi,Ei)(第4行)并获得每个u∈Vi的Ciu。用列表PDi来存储第二集(第7行)的生成(u,Ciu)元组。然后将PDi插入P,表示从所有episodes生成的元组(第8行)。
之后,我们将根据这些生成的元组学习表示。在每个元组(u,Ciu)中,我们考虑每个节点v∈Ciu,我们通过负抽样更新参数(第12-16行)。我们首先更新(u,v)(第13行)的参数:Su,Tv,bu,~bv。然后我们随机抽样一组负实例N(第14行)。接下来,我们更新每个负节点w(第15-16行)的参数:Su,Tw,bu,b〜w。SGD和梯度下降我就不解释了
实验部分
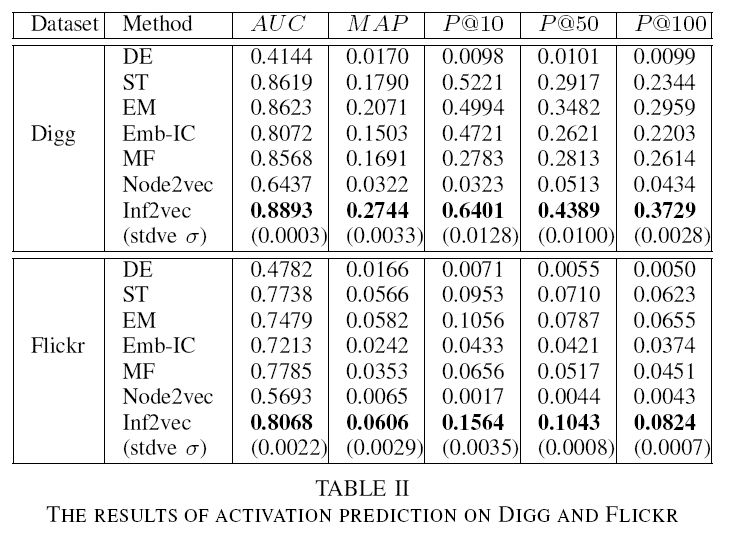
小结
在本文中,我们研究了社会影响嵌入问题,即用潜在向量表示每个用户。我们提出了一种新的算法Inf2vec,它包含三个因素:网络结构,影响传播和用户兴趣的相似性。关键技术贡献在于产生影响环境的方法,其结合了local社会影响背景和全局用户相似性背景。本文对两个真实数据集进行了大量实验。实证结果表明,所提出的Inf2vec模型明显优于基线。未来的探索存在几个有趣的研究问题。
首先,用户的社交行为受到其他因素的影响,例如主题特征。有趣的是开发一些方法来模拟主题感知影响传播。
其次,提议的Inf2vec不限于使用随机游走来生成上下文。我们可以研究其他上下文生成方法,以纳入与社会影响相关的更多因素。
ICDE2018 ·《Inf2vec:Latent Representation Model for Social Influence Embedding》