torch.nn 之 Normalization Layers
torch.nn 是 torch 的神经网络计算部分,其中有许多基础的功能。本文主要记录一下 torch.nn 的 Normalization Layers。
Normalization Layers 部分主要看 nn.BatchNorm2d 和 nn.LayerNorm 两部分。
nn.BatchNorm2d
目标和原理
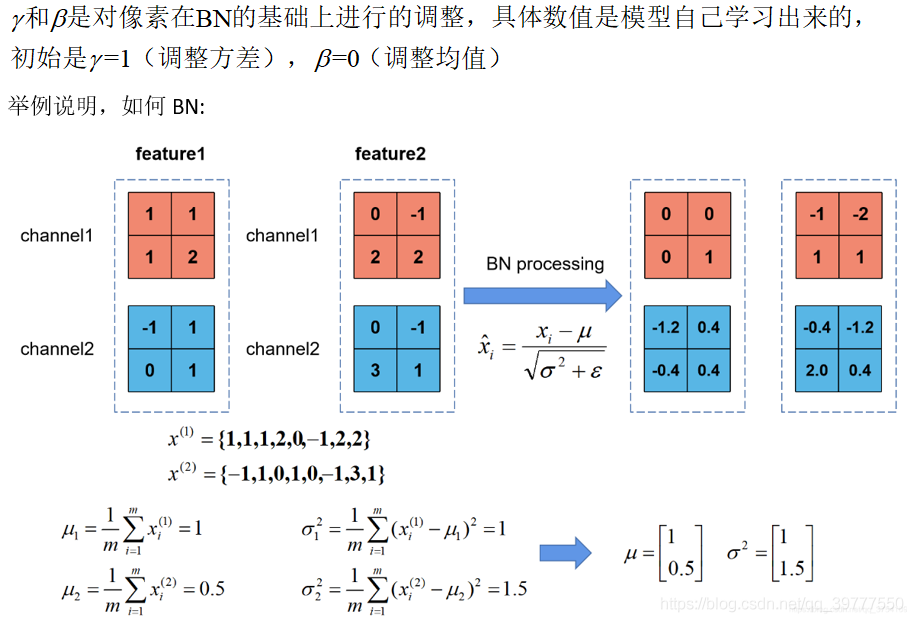
BatchNorm2d 的作用是为了让一批 (batch) 数据通过某种变形成 分布情况均值为 0 ,方差为 1 的数据,且相对大小的情况不改变。
在卷积神经网络的卷积层之后总会添加 BatchNorm2d 进行数据的归一化处理,这使得数据在进行 Relu 之前不会因为数据过大(或者过小)而导致网络性能的不稳定,BatchNorm2d 函数计算方式如下:
因为原始数据经过了 $x-E[x]$ 的均值处理,所以 $y$ 的均值为 $\beta$ ,一般是 0 。方差的计算公式是:

如果把 $y$ 放到方差公式内,可以算出来方差就是 $\gamma$ 一般是 1。
函数参数
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
输入矩阵的维度为 (N, C, H, W) 分别为 batch, channel, height, width
- num_features 是这里的 channel 维度,$\beta$ 和 $\gamma$ 的维度也是这里的 C ,在 (H,W) 这个二维矩阵上做 BatchNorm,所以这里是 2d。
- BatchNorm1d 中 C from an expected input of size (N, C, L) ,后边有一个维度。
- BatchNorm3d 中 C from an expected input of size (N, C, D, H, W),后边有三个维度。
- eps: 分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5
- momentum: 一个用于运行过程中均值和方差的一个估计参数。
- affine: 默认的 $\beta$ 和 $\gamma$ 分别是 0 和 1,这两个是否需要设置为可学习的参数。
- track_running_stats: 如果 BatchNorm2d 的参数 track_running_stats 设置 False,那么加载预训练后每次模型测试测试集的结果时都不一样;track_running_stats 设置为 True 时,每次得到的结果都一样。
运算过程
1 | import torch |
打印的结果为
1 | tensor([[[[-0.6747, -1.2646, -2.3883, -1.1978], |
可以看到 weight 和 bais 分别为维度是 2 的 [1,1] 和 [0,0]。 看一下 input[0][0] 的均值和方差
1 | print("输入的第一个维度:") |
返回结果为
1 | 输入的第一个维度: |
根据 batchNorm2d 的公式,算一下结果
1 | batchnormone=((input[0][0][0][0]-firstDimenMean)/(torch.pow(firstDimenVar,0.5)+m.eps))\ |
返回
1 | tensor(0.0309, grad_fn=<AddBackward0>) |
参考
https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html#torch.nn.BatchNorm2d
https://blog.csdn.net/bigFatCat_Tom/article/details/91619977
https://blog.csdn.net/qq_39777550/article/details/108038677
nn.LayerNorm
layerNorm 基本上和 BatchNorm2d 是很相似的,略微有一点的差异。
函数参数
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
- normalized_shape: 与 input_size 是对应的 ,input_size 应为
[∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]],即 input_size 是 normalized_shape 的后几个维度。
运算过程
LayerNorm 内为二维时,相当于对后边两个维度进行计算。
1 | import torch |
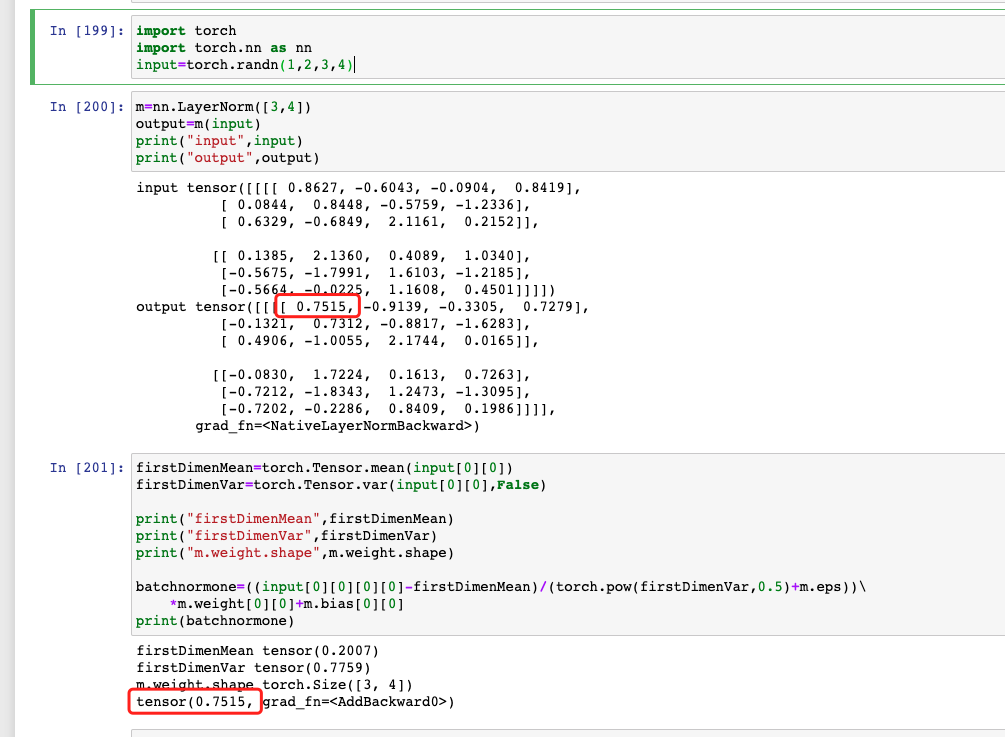
如果 LayerNorm 为一维时
1 | m=nn.LayerNorm([4]) |
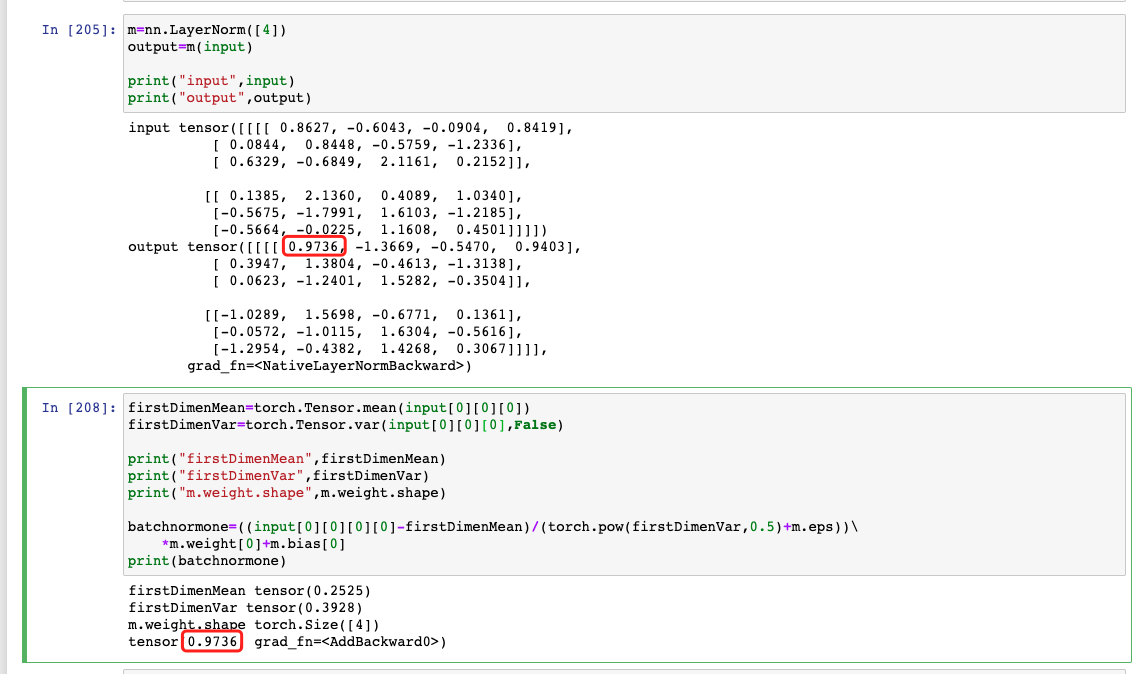
小结
1、一般来说,batch_norm 在大 batch 数据上比较好用,layer_norm 在小数据集上比较好用。 但其实我们可以看到,layer_norm 和 batch_norm 并没有本质上的区别,只是在 norm 的维度上不一样而已。
2、虽然 norm 后的预期是希望生成均值为 0 方差为 1 的数据,但其实并不一定能实现,特别是数据量较小的时候。
3、当方差为0,均值为1时,如果向量一维的,长度为 dim ,则这个向量分布在一个半径为1的超球面上。 这一点很多场景下都有用到。
torch.nn 之 Normalization Layers