Coursera ML(8)-Neural Networks:Learning
本节笔记对应第五周Coursera课程 Neural Networks: Learning
Cost Fuction
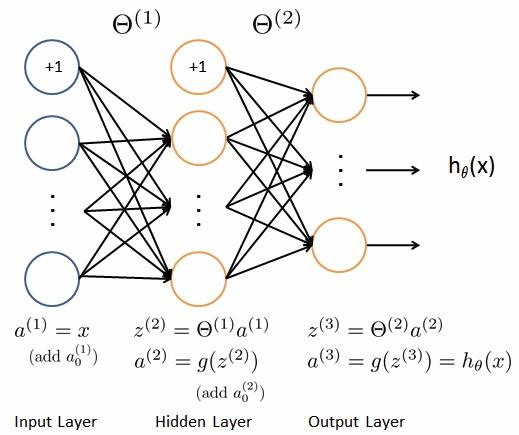
- cost function 我们使用循环,对每一行特征都预测K个不同的结果,然后利用循环在K个预测中选择可能性最高的一个,将其与y中的实际数据进行对比。
- Similarly, the regularization term just sum up the square of all the parameters from all the layers:正则化的这一项,是在排除了每一层$\theta_0$后,每一层的$\Theta$矩阵的和。
- 最里层的循环$j$循环所有的行(由$s_{l+1}$层的激活单元数决定)。
- 循环$i$则循环所有的列,由该层(s_l层)的激活单元数决定。
Note:
这个看起来很复杂的代价函数与之前代价函数思想是一样的,我们希望通过代价函数来观察算法预测的结果与真实情况的误差有多大。不同的是,对于每一行特征,我们都会给出K个预测。
Backpropagation Algorithm
这一块我也看的不是很懂,先不做笔记。之后如果有新的感悟,再记回来。
没有就算了。
最终证明还是可以看懂的,csdn这个sb编辑器,害得我记得笔记丢失了一次,好气哦。又得抄大佬的笔记了。

In order to use optimization algorithms like gradient descent, we must calculate the derivative of the cost function.
- First we should calculate $\delta$ for each layer using backpropagation algorithm.
From $layerl$ to $layer{l+1}$
we have:
误差$\delta$表示激活单元的预测值与实际值之间的误差。第二行式子,是在后一层偏差的基础上,增加了本层的偏差。
注意:没有$\delta_1$
一点感悟
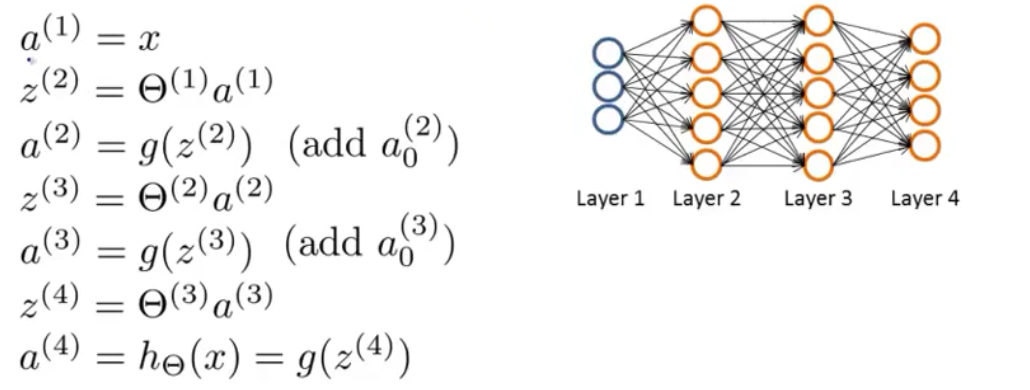

将这两个图,联系在一起,好像对反向传播有了一些理解。其实就是在正向传播的基础上,因为最终的对比结果是在最外层,那么我们从最外层开始,重新纠正一遍计算过程,这样可以减少误差。
For sigmoid function, $g’(z) = g(z)(1-g(z))$
这个比较简单,就不推导了。Then we have the derivative:
在Coursera教程中,这个地方被草草带过,相比之下uci的这篇文章介绍的非常详细。
一个推导过程




另外一个推导
BackPropagation算法
BackPropagation算法是多层神经网络的训练中举足轻重的算法,简单的理解,它就是复合函数的链式法则。由于后面我的网络中会用到对数损失函数,所以在这里我们使用平方损失函数。对于单个样例,其平方损失函数为: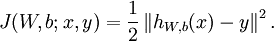
对于给定一个包含m个样例的数据集,我们可以定义整体代价函数为: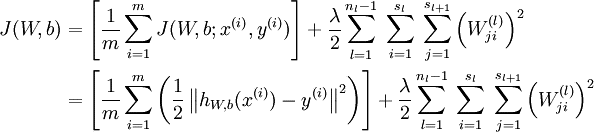
和直线的拟合类似,深度学习也有一个目标函数,通过这个目标函数我们可以知道参数为何值时对我们来说才是一组“好”的参数,这个函数就是前边提到的损失函数。训练的过程就是通过每一次迭代对网络中参数进行更新,来使损失函数的值达到最小(下图中α为学习率)。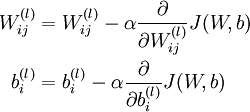
利用BackPropagation算法计算偏导数
由上一节可知,我们只需求出每一层的 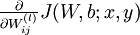 和
和 即可完成该层的权值和偏置的更新。
即可完成该层的权值和偏置的更新。
BP算法的整体思路如下:对于每个给定的训练样本,首先进行前向计算,计算出网络中每一层的激活值和网络的输出。对于最后一层(输出层),我们可以直接计算出网络的输出值与已经给出的标签值(label)直接的差距,我们将这个值定义为残差δ。对于输出层之前的隐藏层L,我们将根据L+1层各节点的加权平均值来计算第L层的残差。
插入一些我个人对BP算法的一点比较容易理解的解释(如有错误请指出):在反向传播过程中,若第x层的a节点通过权值W对x+1层的b节点有贡献,则在反向传播过程中,梯度通过权值W从b节点传播回a节点。不管下面的公式推导,还是后面的卷积神经网络,在反向传播的过程中,都是遵循这样的一个规律。
反向传播的具体步骤如下:
- 根据输入,计算出每一层的激活值。
- 对于输出层,我们使用如下公式计算每个单元的残差:

- 对于输出层之前的每一层,按照如下公式计算每一层的残差:

- 由残差计算每一层的偏导数:
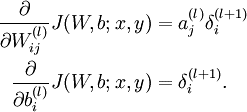
- 最后,使用偏导数更新权值和偏置。
其实说到底,这两个推导方法其实是一回事,只不过换了几个字母而已。第二个推导更好一些
- Instead of calculate the $\Delta$ for all the training data, we could sum up all the inputs independantly, like:
From i = 1 to m, do:Then we have:
(This step is the main step for mapreduce, see Large Scale Machine Learning)
- Then add regularzation term for partial derivative, we have:
- Finally, using $J(\Theta)$ and $\frac {\partial}{\partial \Theta_{ij}^{(l)} } J(\Theta)$, we could minimize the cost function using gradient descent as well as other optimization algorithms.
Optional Section: How Backpropagation Works
Using the same model as the last section:
Let $\deltai^{(2)} =\frac {\partial J}{\partial a_i^{2} } g’(z_i^{(2)})$, then from the result of the first formula We have: $\frac {\partial J}{\partial \Theta{ij}^{1} } =\deltai^{(2)} a_i^{(1)}$, in which recursively, $\delta_i^{(2)} =(\sum\limits{m=1}^{s3}\delta_m^{(3)}\Theta{mi}^{(2)}) g’(z_i^{(2)})$
—
Referance:
http://www.wikiwand.com/en/Backpropagation#Derivation
ttp://blog.csdn.net/l691899397/article/details/52223998
http://xxuan.me/2016-02-20-Neural-Networks-Learning.html
Coursera ML(8)-Neural Networks:Learning